Presupuestos Públicos: del PDF a la visualización
17 Jan 2014Los fines y comienzos de año traen muchas noticias sobre los presupuestos públicos. Los medios comienzan informando sobre los proyectos de presupuesto enviados a las legislaturas por los ejecutivos, luego reportan sobre el debate, y finalmente sobre las inevitables disconformidades de la oposición, sindicatos y privados. Esas coberturas suelen centrarse en las variaciones interanuales de las partidas; tal ministerio subió en un 10% su presupuesto de gastos, y así. Es una gran oportunidad, en general no aprovechada por los medios digitales argentinos, para usar herramientas de visualización de datos que permitan una mejor comprensión de esos cambios presupuestarios. Por el contrario, eligen escribir cosas como “el Ministerio X tendrá asignados 54.234 millones de pesos, lo que representa un incremento del 12.98% con respecto al año pasado“. Es decir, consideran a la web como una hoja de papel y se limitan a traducir a lenguaje escrito lo que podría ser mejor expresado gráfica e interactivamente. Quizás la razón sea que muchos gobiernos, salvo honrosas excepciones, insisten en disponibilizar información pública en formatos muy difíciles de procesar y poco apropiados para el intercambio de información. En este post vamos a tomar como ejemplo los presupuestos de gastos publicados por el gobierno de la provincia de Buenos Aires en formato PDF, el favorito de los funcionarios públicos.
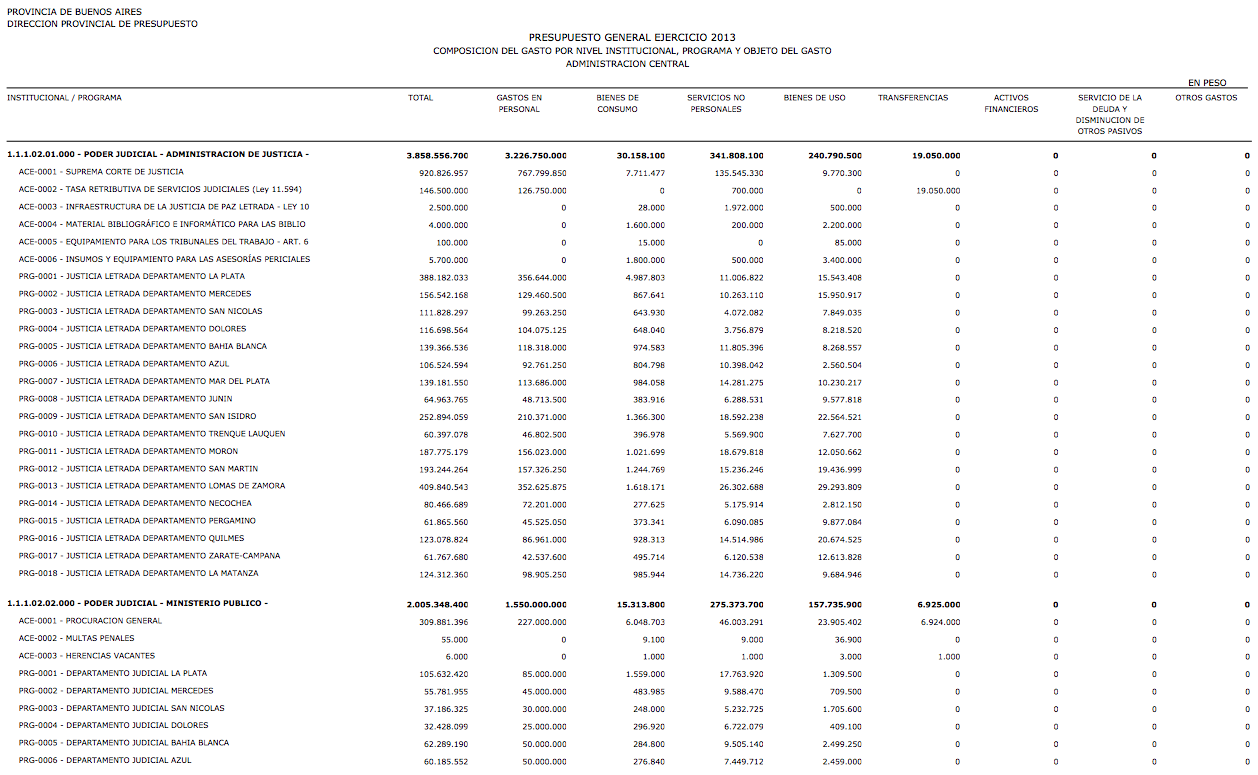 (Primera página del presupuesto de gastos por jurisdicción y objeto (pcia BS.AS, 2013))
(Primera página del presupuesto de gastos por jurisdicción y objeto (pcia BS.AS, 2013))
La imagen anterior es una captura de una página del presupuesto de gastos 2013 de la provincia de Buenos Aires. Queremos visualizar esa información. Si hubiera estado publicada en el formato apropiado, como CSV o inclusive Excel, podríamos habernos puesto manos a la obra. Pero está en PDF, así que vamos a tener que extraer los datos que contiene. Para eso vamos a usar Tabula, una herramienta opensource para liberar tablas atrapadas en PDF que comencé a desarrollar el año pasado. Este video muestra cómo extraer una tabla como la del presupuesto con Tabula:
Vamos a obtener un archivo CSV, que tiene la siguiente estructura:
1.1.1.02.01.000 - PODER JUDICIAL - ADMINISTRACION DE JUSTICIA -,5623235000,5060399000,38500000,229600000,260736000,34000000, 0, 0, 0
ACE-0001 - SUPREMA CORTE DE JUSTICIA,1212978700,1132555800,12520300,56192800,11709800, 0, 0, 0 , 0
ACE-0002 - TASA RETRIBUTIVA DE SERVICIOS JUDICIALES (Ley 11.594),270000000,235300000, 0, 700000, 0,34000000, 0, 0 , 0
ACE-0003 - INFRAESTRUCTURA DE LA JUSTICIA DE PAZ LETRADA - LEY 10,4000000, 0, 100000,3400000, 500000, 0, 0, 0 , 0<
La primer línea representa el primer nivel de desagregación del presupuesto, seguido por el segundo nivel. Cada una de las filas contiene, además, las diferentes componentes del gasto (total, gastos en personal, etc). Para esta visualización, vamos a usar el total de cada partida. Para facilitar el procesamiento vamos a aplanar esta estructura mediante este script en lenguaje Python (pero podríamos haber usado Excel, OpenOffice Calc u OpenRefine):
r = csv.reader(open(sys.argv[1]))
csv_out = csv.writer(sys.stdout)
juris = code_juris = None
for l in r:
if re.match(r'\d\.', l[0]):
s = l[0].split(' - ', 1)
juris = s[1]
code_juris = s[0]
continue
if juris is not None and re.match(r'[A-Z][A-Z][A-Z]-\d+', l[0]):
s = l[0].split(' - ', 1)
csv_out.writerow([code_juris, juris,
code_juris + s[0], s[1]] + [n.replace('.', '') for n in l[1:]])Luego de procesar los datos originales con este programa, obtenemos otro CSV:
1.1.1.02.01.000,PODER JUDICIAL - ADMINISTRACION DE JUSTICIA -,1.1.1.02.01.000ACE-0001,SUPREMA CORTE DE JUSTICIA, 920826957, 767799850, 7711477, 135545330, 9770300, 0, 0, 0 , 0
1.1.1.02.01.000,PODER JUDICIAL - ADMINISTRACION DE JUSTICIA -,1.1.1.02.01.000ACE-0002,TASA RETRIBUTIVA DE SERVICIOS JUDICIALES (Ley 11.594), 146500000, 126750000, 0, 700000, 0, 19050000, 0, 0 , 0
1.1.1.02.01.000,PODER JUDICIAL - ADMINISTRACION DE JUSTICIA -,1.1.1.02.01.000ACE-0003,INFRAESTRUCTURA DE LA JUSTICIA DE PAZ LETRADA - LEY 10, 2500000, 0, 28000, 1972000, 500000, 0, 0, 0 , 0
1.1.1.02.01.000,PODER JUDICIAL - ADMINISTRACION DE JUSTICIA -,1.1.1.02.01.000ACE-0004,MATERIAL BIBLIOGRÁFICO E INFORMÁTICO PARA LAS BIBLIO, 4000000, 0, 1600000, 200000, 2200000, 0, 0, 0 , 0
Vemos que el script aplanó la estructura, incluyendo el primer nivel de desagregación en todas las filas del conjunto de datos resultante. Además, remueve los puntos separadores de miles y genera un identificador único para las partidas de segundo nivel. Con esto, ya estamos listos para subirlo a OpenSpending, el sistema de visualización de datos financieros gubernamentales construído por la Open Knowledge Foundation. No voy a explicar cómo usar OpenSpending; es bastante fácil una vez que se entiende el uso de su data modeler. Lo importante es que, con relativamente poco esfuerzo, podemos ir del PDF a una visualización:
(Visualización Treemap para los datos de composición del Gasto por Nivel Institucional, Programa y Objeto del Gasto — Provincia de Buenos Aires, 2014)
El treemap, una buena manera de representar distribución de magnitudes en datos que tienen jerarquía, es solo una forma posible de representar la información. Según la necesidad, podíamos concentrarnos en la composición del gasto para algunas jurisdicciones, o mostrar variaciones interanuales.