13 Apr 2019 ()
A quick exploration of the music21 toolkit for computational musicology using Charlie Parker’s solos, as transcribed in this MusicXML version of the venerable Omnibook.
No big findings here, just fooling around with the awesome music21 library. If you are interested in serious computational and statistical analysis of jazz solos, head over to the Jazzomat Project
import glob
import music21
import pandas as pd
import functools
import altair as alt
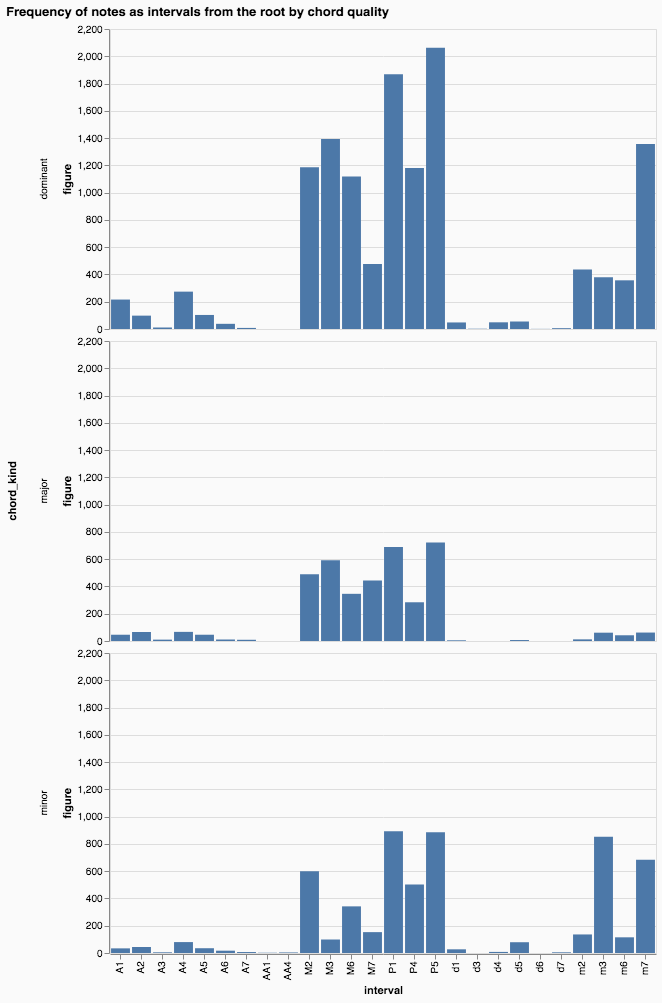
Distribution of notes (expressed as intervals from the chord root) by chord quality
What intervals from the chord root does Bird usually play, depending on the chord’s quality?
@functools.lru_cache(maxsize=4096)
def isChordTone(chord, tone_name):
""" True if note """
return tone_name in [p.name for p in chord.pitches]
notes = []
for fname in glob.glob('Omnibook/MusicXml/*.xml'):
piece = music21.converter.parse(fname)
for m in [m for m in piece.parts[0] if type(m) == music21.stream.Measure]:
currentChord = None
currentChordOffset = None
for thing in m.notesAndRests:
if type(thing) == music21.harmony.ChordSymbol:
currentChord = thing
currentChordOffset = thing.offset
elif type(thing) == music21.note.Note:
if currentChord is None:
continue
interval = music21.interval.Interval(thing.pitch, currentChord.root())
notes.append({
'score': fname,
'measure': m.measureNumber,
'offset': thing.offset,
'chord_kind': currentChord.chordKind,
'figure': currentChord.figure,
'note': thing.name,
'interval': interval.simpleName,
'interval_semitones': interval.chromatic.mod12,
'is_chord_tone': isChordTone(currentChord, thing.name)
})
notes = pd.DataFrame(notes)
data = notes.groupby(['chord_kind', 'interval']).count().reset_index()
alt.Chart(data[data.chord_kind.isin(['dominant', 'major', 'minor'])]).mark_bar().encode(
x='interval:N',
y='figure:Q',
row='chord_kind'
).configure(background='#fafafa') \
.properties(title="Frequency of notes as intervals from the root by chord quality")
12 Aug 2017 ()
Esta semana, la Dirección Nacional de Datos e Información Pública publicó “Tu nombre en los últimos 100 años”, un sitio muy divertido que permite consultar frecuencias de uso de nombres propios. Parecido al Popular Baby Names de la Social Security Administration de Estados Unidos. Junto con el sitio, el equipo de datos públicos subió el dataset al portal de datos públicos.
El diario La Nación publicó un enlace al sitio de nombres en su home page…y se vino abajo por el tráfico.
Para poner a andar un ratito la croqueta, me puse a pensar cómo hacer un método eficiente de consulta de esta información. Dado uno o varios nombres, quiero obtener la serie temporal de sus frecuencias. No es nada del otro mundo, y es apenas un prototipo.
Preparando el dataset
cat historico-nombres.csv | uconv -t ASCII -x nfd -c | tr '[:upper:]' '[:lower:]' | tr -s ' ' | sed -e 's/^ *//' -e 's/ *$//' | csvfix sort -smq -rh -f 1:S,3:N > sorted-ascii-historico-nombres.csv
Ese pipeline de comandos procesa el archivo original aplicando las siguientes transformaciones:
uconv -t ASCII -x nfd -c: Aplicar la forma de normalización Canonical Decomposition de Unicode (NFD). En criollo, sacarle acentos a los caracterestr '[:upper:]' '[:lower:]': pasar todo a minísculastr -s ' ': convertir espacios repetidos a uno sólo.sed -e 's/^ *//' -e 's/ *$//': sacar espacios del principio y final de cada línea.csvfix sort -smq -rh -f 1:S,3:N: ordenar la tabla según nombre y luego año.
Nos queda algo así:
| nombre |
cantidad |
anio |
| aage tomasen |
2 |
1931 |
| aago peter |
1 |
1987 |
| aakash |
2 |
1985 |
| aalam yamir |
2 |
2013 |
| aale rene |
1 |
1987 |
| aalejandro daniel |
1 |
2002 |
| aaleyah nayara |
2 |
2013 |
Una estructura eficiente
Lo más simple que se me ocurrió es pivotear ese dataset, para convertirlo en una matriz donde cada fila es un nombre y cada columna es un año. Tenemos 3044402 nombres únicos y un período de 94 años. Es decir, una matriz de 3044402 x 94.
Para poder obtener la fila correspondiente al nombre que nos interesa, también construimos un diccionario NAMES cuyas claves son los nombres y sus valores el índice de la fila de la matriz que contiene la serie temporal de frecuencias.
El siguiente script construye esas estructuras de datos.
# coding: utf-8
import csv, sys, pickle
import numpy as np
YEAR_MIN, YEAR_MAX = 1922, 2015
YEARS_Q = YEAR_MAX - YEAR_MIN
NAMES_Q = 3044402 # count-distinct on the name column
NAMES = {}
FREQS = np.zeros((NAMES_Q, YEARS_Q+1), int)
reader = csv.reader(sys.stdin)
next(reader) # skip header
# Pivotear el dataset de nombres:
# a partir de una tabla de (nombre, frecuencia, año), construir una matriz
# de frecuencias |nobmres| x |años|
cur_name, cur_row, i = None, None, -1
for row in reader:
if row[0] != cur_name:
i += 1
NAMES[row[0]] = i
if i % 2000 == 0:
print("%d names processed" % i)
FREQS[i, int(row[2]) - YEAR_MIN] += int(row[1])
cur_name = row[0]
# save FREQS
np.save('freqs', FREQS)
# save NAMES
with open('names.pickle', 'wb') as f:
pickle.dump(NAMES, f)
Consultando las frecuencias
Cómo consultamos esto? Fácil. Obtenemos el índice del nombre que nos interesa, y con él, la fila correspondiente en la matriz:
import numpy as np
import pickle
FREQS = np.load('freqs.npy')
with open('names.pickle', 'rb') as f:
NAMES = pickle.load(f)
array([ 56, 2, 119, 122, 2, 1, 4, 231, 6, 2, 326,
268, 330, 1, 330, 332, 6, 356, 3, 3, 4, 2,
3, 494, 464, 510, 8, 4, 1, 365, 374, 3, 317,
3, 3, 308, 3, 253, 8, 5, 1, 1, 1, 180,
167, 3, 161, 151, 193, 156, 144, 173, 5, 223, 269,
4, 242, 2, 3, 238, 268, 8, 1, 436, 456, 415,
487, 458, 566, 627, 555, 801, 1013, 1135, 1012, 783, 786,
760, 729, 678, 736, 815, 2, 0, 718, 726, 705, 650,
581, 600, 814, 789, 849, 711])
Visualizamos el resultado para verificar que al menos se parezca a lo que reporta el sitio oficial. Para esto, también vamos a calcular el pormilaje (?) del nombre de interés para cada año. Con los datos en esta matriz, es fácil: la cantidad de nombres en cada año es la suma de cada columna.
manuel_1000ct = (FREQS[NAMES['manuel']] / np.sum(FREQS, axis=0)) * 1000
from altair import Chart, Bin, X, Axis
import pandas as pd
data = pd.DataFrame({'year': list(range(1922,2016)), 'freq': manuel_1000ct})
chart = Chart(data).mark_line().encode(
x='year:N',
y='freq:Q',
)
chart
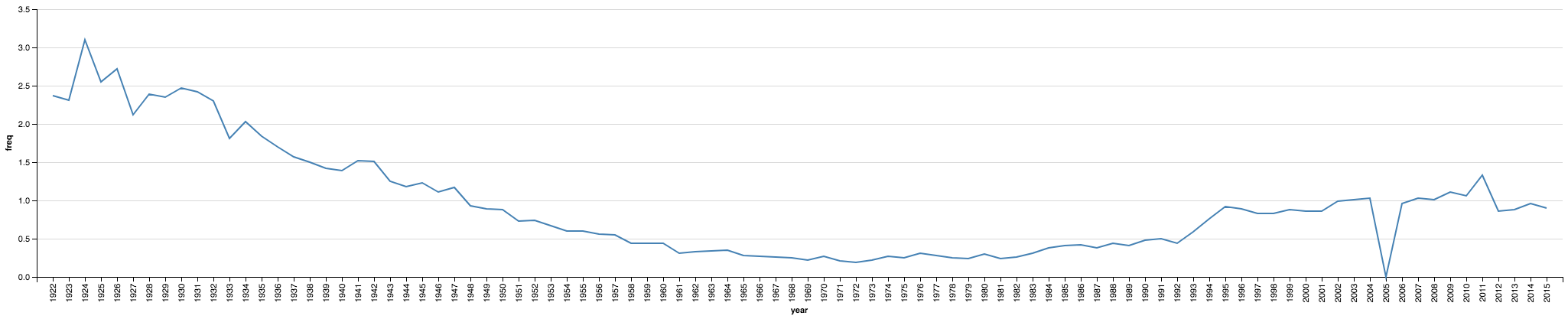
Es parecido, pero no igual 😔. El 0 en 2005 no coincide con la fuente, sospecho algun problema de comparacion de strings.
Mirá, mamá: sin base de datos.
El tamaño de la matriz FREQS es relativamente chico, apenas 2.13 gigabytes en memoria.
El diccionario de nombres (NAMES) tampoco ocupa mucho; 160 megabytes.
sys.getsizeof(NAMES) / 1024**2
Este pequeño ejercicio se puede exponer a través de un endpoint HTTP muy simple que mantenga esta matriz numpy en memoria y envíe los datos serializados en la respuesta.
Con eso, estimo, se pueden mejorar bastante la estabilidad y robustez del servicio
[El código está disponible aquí: https://gist.github.com/jazzido/1050fd9169adb7fd9ff1d1002649fd16]
03 Apr 2017 ()
Han ocurrido muchas cosas desde los primeros esfuerzos para construir recursos de información basados en datos públicos gubernamentales. Desde Dinero y Política, esfuerzo fundacional de Gonzalo Iglesias y Poder Ciudadano, y Gasto Público Bahiense (GPB) —de quien escribe—, algunos gobiernos en Argentina adoptaron políticas de transparencia acompañadas de implementaciones de herramientas online. Pese a estos 8 años de historia y evolución en el país, los resultados son bastante pobres. Los proyectos surgidos de la sociedad civil tienen problemas de sustentabilidad, el sector privado no se interesa en el tema, y el sector público tiene un enorme déficit en su capacidad de construir servicios públicos digitales.
El uso de los recursos públicos es una de las fuentes de información más importantes que genera el gobierno en cualquiera de sus niveles. En particular, el presupuesto y su ejecución quizás sea el dataset más valioso que produce y mantiene una administración pública. Las prioridades de la poltica pública, en definitiva, pueden verse a través del uso de los recursos que hace un gobierno.
Un sistema que corre en al menos 135 municipios
Unas de las primeras veces que hablé públicamente sobre GPB fue hace casi 7 años en el Hackatón de Datos Públicos y Gobierno Abierto que organizamos con Garage Lab junto al Programa de Gobierno Electrónico de la Universidad de San Andrés. Hay video de esa charla. Durante el evento de dos días, que recuerdo como el mejor hackatón al que haya asistido, alguien me comentó que la información administrativa (presupuestos, personal, tasas, etc) de los 135 municipios bonaerenses se almacenaba en un sistema llamado RAFAM, que corre en todos los partidos de la provincia. Con la ingenuidad que tenemos los ingenieros con poca experiencia en política, dijimos —«Obvio! Hay que escribir software que extraiga los datos de esos 135 servidores Oracle, convencer a los intendentes que lo instalen, y ya está: información fiscal para todos y todas». Para eso, necesitábamos acceder a alguno de esos sistemas para poder hacer la ingeniería reversa correspondiente. No llegamos muy lejos; como suele suceder en muchos esfuerzos voluntaristas el entusiasmo se fue apagando luego del hackatón. Además, los contactos iniciales con algunos municipios nos hicieron pensar que ningún secretario de hacienda iba a darnos acceso irrestricto a su sistema contable para poder reversearlo.
Pero la idea de un componente de software que fuese capaz de extraer datos de 135 bases de datos municipales era demasiado potente como para dejarla ir así no más.
La conexión bahiense
Ya he contado la historia muchas veces: cuando lancé GPB, el gobierno municipal estaba abiertamente en contra de la iniciativa. La nueva administración que asumiría en 2012, en cambio, creó una de las primeras oficinas dedicadas a la innovación y gobierno abierto del país con la que tuve excelente relación desde el comienzo hasta el nuevo cambio de intendente a fines de 2015. Fue con esa dependencia, a través de su secretario Esteban Mirofsky, que organizamos otro hackatón del que surgieron proyectos pioneros como un sistema de información ambiental en tiempo real y un prototipo de plataforma de información basada en los datos de la tarjeta de transporte. Sobre este último, escribí un blog post y, junto a Cristian Jara Figueroa, un trabajo final para un curso de modelos de movilidad humana que tomé durante mi maestría en MIT.
El último proyecto en el que colaboré con la Agencia de Innovación y Gobierno Abierto fue una plataforma para visualizar prespuestos públicos, en el marco de mi tesis de maestría. Finalmente, 5 años después del mítico hackatón de 2010, un municipio bonaerense estuvo dispuesto a darme acceso a su sistema RAFAM para estudiarlo y poder extraer la información que almacena.
Levantando el capot de RAFAM
Pensaba que escribir las consultas SQL para extraer datos de RAFAM sería una tarea relativamente fácil, pero fui víctima una vez más del optimismo del que sufrimos los ingenieros. Cuando me conecté a esa base de datos, me encontré con un sistema con casi 2000 tablas, cientos de vistas y miles de stored procedures. No iba a ser tan fácil.
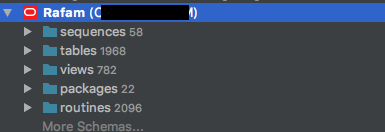
Por suerte, el Ministerio de Economía de la provincia de Buenos Aires publica en su sitio web actualizaciones del sistema RAFAM, que contienen archivos de Crystal Reports. Estos, a su vez, contienen las queries necesarias para generar diversos reportes. Entre ellos, estaban los que nos interesan: ejecución presupuestaria.
Armados con esta información, junto al Dr. Gastón Ávila escribimos una serie de queries que permitieron extraer tablas del estado de ejecución presupuestaria —tanto de gastos como de recursos— desagregadas según todos los criterios en los que se clasifica un presupuesto público (ver mi post anterior sobre el tema)
¿Y el código?
Siempre tuve la intención de liberar el código de Presupuesto Abierto y SpendView, ambos desarrollados dentro de mi tesis de maestría. El optimismo ingenieril otra vez al ataque: el código escrito frenéticamente durante una carrera de posgrado está lejos de ser publicable, pero quiero empezar con ese proceso más temprano que tarde. Hoy comienzo publicando el código del programa que sirve para extraer los datos de ejecución presupuestaria de una instancia de RAFAM. Consiste en dos módulos escritos en lenguaje Python.
rafam_db: encapsula las consultas SQL que escribimos basándonos en los reportes que genera el sistema RAFAM.rafam_extract: comando para ejecutar las consultas del modulo rafam_db
Si este código aporta algún valor (espero que sí), está en las consultas SQL. Los comandos escritos en Python son bastante genéricos, y no es necesario usarlos.
El código está en mi perfil de GitHub: https://github.com/jazzido/openrafam
¿Para qué sirve todo esto?
Pese a los anuncios grandilocuentes, los eventos, los subsidios y los hackatones, los servicios públicos basados en datos avanzaron muy poco en los ~8 años de historia del movimiento de datos abiertos en Argentina. Estoy convencido de que la falta de voluntad política es la razón más importante, pero también la falta de capacidades técnicas en el sector público.
Quizás, ayudando desde afuera con lo que sabemos hacer (programar), animemos a los municipios a construir sistemas de información basados en datos tanto para consumo interno como externo.
08 Feb 2017 ()
Los códigos de barras de los productos que compramos contienen información sobre la empresa que los distribuye, empaca o fabrica. En este breve ejercicio, vamos a intentar combinar una lista de productos tomada del sitio público Precios Claros con una lista de compañías compilada por el proyecto Product Open Data.
Los identificadores de productos en preciosclaros.gob.ar son, en la mayoría de los casos, el código de barras del producto. Para extraer el campo GCP (Global Company Prefix) del identificador, vamos a usar la librería gtin.
import pandas as pd
from gtin import GTIN
Leemos la lista de productos, y agradecemos a nuestro anónimo amigo que se tomó el trabajo de scrapear Precios Claros.
df = pd.read_csv('productos_precios_claros.csv')
df.loc[:, 'uuid'] = df.uuid.apply(lambda s: s.split('producto-')[1])
Agregamos una columna que contendrá, si es posible, el campo GCP.
def gg(gtin):
try:
g = GTIN(gtin)
except:
return None
try:
return g.get_gcp()
except:
return None
df.loc[:, 'gcp'] = df.uuid.apply(lambda u: gg(u))
Calculamos una agregación de la tabla anterior, calculando dos variables adicionales:
marca: un conjunto de marcas asociadas a un GCPproduct_count: cantidad de productos asociados a un GCP
products_by_gcp = df \
.groupby(['gcp'], as_index=False) \
.agg({
'marca': lambda m: set(m),
'uuid': 'count'
}) \
.rename(columns={'uuid': 'product_count'}) \
.sort_values(by='product_count', ascending=False)
Leemos la base de datos de GCPs obtenida de Product Open Data. Lamentablemente, la última versión es de 2013 y su cobertura para fabricantes argentinos es bastante mala.
gepir = pd.read_csv('/Users/manuel/Downloads/gs1_gcp.csv',
dtype={'GCP_CD': str, 'GLN_CD': str},
low_memory=False)
…y la combinamos con nuestra lista de GCPs (products_by_gcp).
merged = products_by_gcp.merge(gepir, how='inner', left_on='gcp', right_on='GCP_CD')
Verificamos qué porcentaje de GCPs pudimos encontrar en la base de datos:
n_matched_gcps = len(merged[~merged.GLN_NM.isnull()])
total_gcps = len(products_by_gcp)
print((n_matched_gcps / total_gcps) * 100)
Filtramos la lista para mostrar solamente las compañías que pudimos encontrar
out = merged[~merged.GLN_NM.isnull()][['gcp', 'product_count', 'marca', 'GLN_NM', 'GLN_COUNTRY_ISO_CD']]
Le agregamos la bandera del país para que quede más cheto.
OFFSET = ord('🇦') - ord('A')
def flag(code):
return chr(ord(code[0]) + OFFSET) + chr(ord(code[1]) + OFFSET)
out.loc[:, 'country_flag'] = out['GLN_COUNTRY_ISO_CD'].apply(flag)
pd.set_option('display.max_rows', len(out))
out
|
gcp |
product_count |
marca |
GLN_NM |
GLN_COUNTRY_ISO_CD |
country_flag |
| 0 |
8480017 |
1009 |
{GROLS, CUQUE, NAN, CARO AMICI, S.OND, CROCK, ... |
DIA |
ES |
🇪🇸 |
| 2 |
4005808 |
29 |
{NIVEA} |
Beiersdorf AG |
DE |
🇩🇪 |
| 3 |
0070330 |
18 |
{BIC , BIC} |
BIC USA Inc. |
US |
🇺🇸 |
| 5 |
4052899 |
10 |
{OSRAM, DULUX} |
OSRAM GmbH CRM&S MDS P-W |
DE |
🇩🇪 |
| 6 |
301426 |
10 |
{ZOOTH, GILLETTE, ORAL B} |
PROCTER ET GAMBLE FRANCE SAS |
FR |
🇫🇷 |
| 9 |
75010074 |
7 |
{KOLESTON, ALWAYS, PANTENE} |
CORPORATIVO PROCTER & GAMBLE, S. DE R.L. DE C.... |
MX |
🇲🇽 |
| 10 |
4008321 |
7 |
{OSRAM, DULUX} |
OSRAM GmbH |
DE |
🇩🇪 |
| 12 |
75010067 |
6 |
{PAMPERS, PANTENE} |
CORPORATIVO PROCTER & GAMBLE, S. DE R.L. DE C.... |
MX |
🇲🇽 |
| 13 |
7509546 |
6 |
{PROTEX, COLGATE, PALMOLIVE} |
COLGATE PALMOLIVE, S.A. DE C.V. COLGATE PALMOLIVE |
MX |
🇲🇽 |
| 14 |
0038000 |
6 |
{PRINGLES} |
Kellogg Company |
US |
🇺🇸 |
| 15 |
8413600 |
5 |
{VEET} |
RECKITT BENCKISER |
ES |
🇪🇸 |
| 16 |
0047400 |
5 |
{GILLETTE} |
Procter & Gamble Company |
US |
🇺🇸 |
| 17 |
75010092 |
5 |
{GILLETTE, PRESTOBARBA} |
NEWELL RUBBERMAID DE MEXICO, S. DE R.L. DE C.V... |
MX |
🇲🇽 |
| 18 |
75010563 |
5 |
{PONDS, SEDAL} |
UNILEVER DE MEXICO, S. DE R.L. DE C.V. UNILEVER |
MX |
🇲🇽 |
| 19 |
4005900 |
5 |
{NIVEA} |
Beiersdorf AG |
DE |
🇩🇪 |
| 20 |
0041789 |
5 |
{MARUCHAN} |
Maruchan, Inc. |
US |
🇺🇸 |
| 21 |
75010592 |
4 |
{COFFEE MATE, NESCAFE} |
NESTLE MEXICO, S.A. DE C.V. NESTLE MEXICO, S.A... |
MX |
🇲🇽 |
| 22 |
0000075 |
4 |
{CORONA, DOVE, REXONA} |
ASOCIACION MEXICANA DE ESTANDARES PARA EL COME... |
MX |
🇲🇽 |
| 23 |
0041333 |
4 |
{DURAC} |
Procter & Gamble Company |
US |
🇺🇸 |
| 24 |
0084773 |
4 |
{ROBINSON CRUSOE} |
Trans Antartic Trading Co Ltda |
CL |
🇨🇱 |
| 25 |
8718291 |
3 |
{PHILI} |
Philips Electronics Nederland B.V. |
NL |
🇳🇱 |
| 26 |
75010011 |
3 |
{HEAD & SHOULDERS, PANTENE} |
CORPORATIVO PROCTER & GAMBLE, S. DE R.L. DE C.... |
MX |
🇲🇽 |
| 27 |
0040000 |
3 |
{M & M, SKITTLES} |
Mars Chocolate North America LLC |
US |
🇺🇸 |
| 29 |
8710163 |
3 |
{PHILI} |
Philips Electronics Nederland B.V. |
NL |
🇳🇱 |
| 30 |
8710103 |
3 |
{PHILI} |
Philips Electronics Nederland B.V. |
NL |
🇳🇱 |
| 31 |
0000080 |
3 |
{KINDER} |
Indicod-Ecr - GS1 Italy |
IT |
🇮🇹 |
| 32 |
75010086 |
2 |
{BACARDI} |
BACARDI Y COMPAÑIA, S.A. DE C.V. BACARDI |
MX |
🇲🇽 |
| 33 |
75010012 |
2 |
{HEAD & SHOULDERS} |
CORPORATIVO PROCTER & GAMBLE, S. DE R.L. DE C.... |
MX |
🇲🇽 |
| 34 |
75010013 |
2 |
{OLD SPICE, PANTENE} |
CORPORATIVO PROCTER & GAMBLE, S. DE R.L. DE C.... |
MX |
🇲🇽 |
| 35 |
9044400 |
2 |
{PEZ} |
PEZ International GmbH |
AT |
🇦🇹 |
| 36 |
8712581 |
2 |
{PHILI} |
Philips Electronics Nederland B.V. |
NL |
🇳🇱 |
| 37 |
75010864 |
2 |
{PRO} |
CORPORATIVO PROCTER & GAMBLE, S. DE R.L. DE C.... |
MX |
🇲🇽 |
| 38 |
7591083 |
2 |
{COLGATE} |
COLGATE-PALMOLIVE C.A |
VE |
🇻🇪 |
| 39 |
0021200 |
2 |
{SCOTCH BRITE} |
3M Company |
US |
🇺🇸 |
| 41 |
0071603 |
2 |
{TRIM} |
Pacific World Corporation |
US |
🇺🇸 |
| 42 |
08452180 |
2 |
{VULCA, SIN MARCA} |
GS1 China |
CN |
🇨🇳 |
| 43 |
0070501 |
2 |
{NEUTROGENA} |
Neutrogena Corporation |
US |
🇺🇸 |
| 44 |
0022000 |
2 |
{WRIGLEYS} |
Wm. Wrigley Jr. Company |
US |
🇺🇸 |
| 45 |
4015400 |
2 |
{PAMPERS} |
Procter & Gamble GmbH Wasch- u. Reinigungsmittel |
DE |
🇩🇪 |
| 46 |
0079400 |
2 |
{REXONA} |
Unilever Home and Personal Care USA |
US |
🇺🇸 |
| 47 |
5000329 |
2 |
{BEEFEATER} |
Chivas Brothers Limited |
GB |
🇬🇧 |
| 48 |
0012800 |
1 |
{RAYOV} |
Spectrum Brands, Inc. |
US |
🇺🇸 |
| 49 |
9002490 |
1 |
{RED BULL} |
Red Bull GmbH |
AT |
🇦🇹 |
| 50 |
0079200 |
1 |
{NERDS} |
Sunmark |
US |
🇺🇸 |
| 51 |
0000040 |
1 |
{KINDER} |
Nestlé Deutschland AG |
DE |
🇩🇪 |
| 52 |
0070942 |
1 |
{GUM} |
Sunstar Americas, Inc. |
US |
🇺🇸 |
| 53 |
8412300 |
1 |
{NIVEA} |
BEIERSDORF MANUFACTURING TRES CANTO |
ES |
🇪🇸 |
| 54 |
8715200 |
1 |
{NIVEA} |
Beiersdorf N.V. |
NL |
🇳🇱 |
| 55 |
0051000 |
1 |
{sin marca} |
Campbell Soup Company |
US |
🇺🇸 |
| 57 |
0080432 |
1 |
{CHIVAS REGAL} |
Pernod Ricard USA LLC |
US |
🇺🇸 |
| 58 |
0016304 |
1 |
{SIN MARCA} |
Unofficial Guides Ltd. |
US |
🇺🇸 |
| 59 |
0013000 |
1 |
{HEINZ} |
Heinz USA |
US |
🇺🇸 |
| 60 |
0099176 |
1 |
{COLGATE} |
Colgate Palmolive (Central America) S.A. |
GT |
🇬🇹 |
| 61 |
0090159 |
1 |
{MAIST} |
May Cheong Toy Products Factory Limited |
HK |
🇭🇰 |
| 62 |
75010587 |
1 |
{sin marca} |
RECKITT BENCKISER MEXICO, S.A. DE C.V. RECKITT... |
MX |
🇲🇽 |
| 63 |
5900273 |
1 |
{COLGATE} |
Colgate-Palmolive (Poland) Sp. z o.o. |
PL |
🇵🇱 |
| 64 |
5410316 |
1 |
{SMIRNOFF} |
DIAGEO SCOTLAND LTD |
GB |
🇬🇧 |
| 65 |
5011013 |
1 |
{BAILEYS} |
GS1 Ireland |
IE |
🇮🇪 |
| 66 |
5010103 |
1 |
{J&B} |
Diageo PLC |
GB |
🇬🇧 |
| 67 |
75010080 |
1 |
{CHOCO KRISPIS } |
KELLOGG COMPANY MEXICO, S. DE R.L.DE C.V. KELLOGG |
MX |
🇲🇽 |
| 68 |
75010152 |
1 |
{PELIK} |
PELIKAN MEXICO, S.A. DE C.V. PELIKAN |
MX |
🇲🇽 |
| 69 |
75010329 |
1 |
{GLADE} |
S.C. JOHNSON AND SON S.A. DE C.V. S.C. JOHNSON... |
MX |
🇲🇽 |
| 70 |
4006584 |
1 |
{L.B.L} |
OSRAM GmbH CRM&S MDS P-W |
DE |
🇩🇪 |
| 71 |
75010641 |
1 |
{CORONA} |
CERVECERIA MODELO, S. DE R.L. DE C.V. CERVECER... |
MX |
🇲🇽 |
| 72 |
4005800 |
1 |
{NIVEA} |
Beiersdorf AG |
DE |
🇩🇪 |
| 73 |
303371 |
1 |
{NESCAFE} |
NESTLE FRANCE SAS |
FR |
🇫🇷 |
| 74 |
0742832 |
1 |
{AOC} |
Tufftek |
US |
🇺🇸 |
| 76 |
0681326 |
1 |
{SIN MARCA} |
Jazwares |
US |
🇺🇸 |
| 77 |
7590002 |
1 |
{ALWAYS} |
PROCTER & GAMBLE DE VENEZUELA, S.C.A. |
VE |
🇻🇪 |
El notebook completo está disponible acá: https://gist.github.com/jazzido/35990ebf8c236d3df953eb1f0af9e39c
09 Jan 2017 ()
Cada vez que el INDEC publica datos de la Encuesta Permanente de Hogares (EPH), hay repercusiones mediáticas de algunas de las variables que mide esa encuesta. El ingreso suele ser de particular interés para la cobertura periodística, por ejemplo en esta nota de La Nación.
Esos artículos, en general, usan como fuente a los “cuadros” que publica el INDEC. Esos cuadros contienen estadísticas calculadas a partir de los registros individuales de la EPH. Es decir, las repuestas de cada individuo que fue encuestado. A esas tablas, en la jerga, se las llama microdatos.
Inspirado por el post de Pablo Fernández en el que analizó los cuadros de población según escala de ingreso individual para el tercer trimestre de 2016, voy a intentar reproducirlos a partir de los microdatos de la EPH. Vamos a usar el lenguaje de programación Python, y la librería de análisis y manipulación de datos pandas.
A diferencia de otros organismos de estadística pública, como las APIs del Census Bureau de Estados Unidos, el INDEC no ofrece demasiada sistematización para obtener las bases de datos. El sistema de distribución de esa información es un rudimentario download de un archivo ZIP, que contiene las tablas en formato TXT o Excel. Vamos a trabajar con el último dataset disponible a la fecha, que corresponde al segundo trimestre de 2016.
Una vez abierto el archivo ZIP, leemos la tabla de respuestas de individuos.
eph = pd.read_excel('usu_individual_T216.xls')
Queremos reproducir un cuadro de población total según escala de ingreso individual. Consultamos el documento de Diseño de Registro y Estructura para las bases preliminares Hogar y Personas y vemos que la variable que contiene el monto de ingreso total individual se llama P47T. Filtramos la tabla y obtenemos los registros que declaran algún ingreso. Esto es, aquellos en los que P47T > 0.
with_income = eph[eph['P47T'] > 0]
Dado que las encuestas como la EPH contienen una muestra de la población, las variables suelen estar ponderadas (weighted) por un factor de ajuste que debemos usar para el cálculo de estadísticas. Para tratar el ingreso total individual, la EPH provee la variable PONDII, documentada en el Anexo I del documento de diseño.
El decil o grupo decílico para el ingreso total individual, ya está provisto por la EPH en la variable DECINDR, pero no contiene los límites de cada uno. Los calculamos con la ayuda de la librería weightedcalcs.
import weightedcalcs
upper = []
lower = []
wc = weightedcalcs.Calculator('PONDII')
lowerb = with_income['P47T'].min()
for q in range(1,11):
upperb = wc.quantile(with_income, 'P47T', q/10.0)
lower.append(lowerb)
upper.append(upperb)
lowerb = upperb
deciles = pd.DataFrame({'lbound': lower, 'ubound': upper}).reset_index().rename(columns={'index': 'decile'})
deciles['decile'] = deciles['decile'] + 1
Verificamos que las cotas de los deciles son iguales a los del cuadro que estamos replicando:
|
decile |
lbound |
ubound |
| 0 |
1 |
22.0 |
2470.0 |
| 1 |
2 |
2470.0 |
4000.0 |
| 2 |
3 |
4000.0 |
4800.0 |
| 3 |
4 |
4800.0 |
6000.0 |
| 4 |
5 |
6000.0 |
7200.0 |
| 5 |
6 |
7200.0 |
9000.0 |
| 6 |
7 |
9000.0 |
10500.0 |
| 7 |
8 |
10500.0 |
14000.0 |
| 8 |
9 |
14000.0 |
20000.0 |
| 9 |
10 |
20000.0 |
715000.0 |
Usamos el grupo decílico provisto en la tabla para agregarle los intervalos de cada uno que acabamos de calcular.
with_income = with_income.merge(deciles, left_on='DECINDR', right_on='decile')
Sumando el ponderador (PONDII) para cada grupo decílico, obtenemos la población de cada uno. Creamos un nuevo DataFrame en el que almacenaremos las variables del cuadro que estamos replicando.
cuadro = pd.DataFrame(with_income.groupby('DECINDR')['PONDII'].sum()).rename(columns={'PONDII': 'decile_population'})
Agregamos una variable con el ingreso total de cada decil.
with_income.loc[:, 'weighted_income'] = with_income['P47T'] * with_income['PONDII']
cuadro['decile_total_income'] = pd.DataFrame(with_income.groupby('DECINDR')['weighted_income'].sum() / 1000)
Agregamos otra con el porcentaje del ingreso de cada decil sobre el ingreso total
cuadro['decile_percentage_income'] = (cuadro['decile_total_income'] / cuadro['decile_total_income'].sum()) * 100
Calculamos el ingreso medio por decil
cuadro['decile_mean_income'] = cuadro['decile_total_income'] / cuadro['decile_population']
Finalmente, agregamos las cotas de cada decil
cuadro = cuadro.reset_index().merge(deciles, left_on='DECINDR', right_on='decile').rename(columns={'lbound': 'decile_lower_bound', 'ubound': 'decile_upper_bound'})
del cuadro['decile']
Como decía la revista Anteojito, acá el modelo terminado:
|
DECINDR |
decile_population |
decile_total_income |
decile_percentage_income |
decile_mean_income |
decile_lower_bound |
decile_upper_bound |
| 0 |
1 |
1618265 |
2.121558e+06 |
1.350246 |
1.311008 |
22.0 |
2470.0 |
| 1 |
2 |
1616771 |
5.337631e+06 |
3.397086 |
3.301414 |
2470.0 |
4000.0 |
| 2 |
3 |
1617945 |
7.243509e+06 |
4.610064 |
4.476981 |
4000.0 |
4800.0 |
| 3 |
4 |
1615707 |
8.257147e+06 |
5.255185 |
5.110547 |
4800.0 |
6000.0 |
| 4 |
5 |
1617192 |
1.046035e+07 |
6.657395 |
6.468220 |
6000.0 |
7200.0 |
| 5 |
6 |
1617391 |
1.318178e+07 |
8.389421 |
8.150026 |
7200.0 |
9000.0 |
| 6 |
7 |
1617847 |
1.577172e+07 |
10.037767 |
9.748588 |
9000.0 |
10500.0 |
| 7 |
8 |
1616376 |
1.957398e+07 |
12.457680 |
12.109795 |
10500.0 |
14000.0 |
| 8 |
9 |
1617180 |
2.605983e+07 |
16.585536 |
16.114364 |
14000.0 |
20000.0 |
| 9 |
10 |
1617037 |
4.911631e+07 |
31.259620 |
30.374264 |
20000.0 |
715000.0 |
Por supuesto, este ejercicio es apenas un ejemplo de lo que se puede hacer con los microdatos de la Encuesta Permanente de Hogares. El procesamiento de otras variables queda como actividad para el lector entusiasta.
El notebook completo está disponible acá: https://gist.github.com/jazzido/d067c834d0990fe3cf932cf6e7ec1881