18 Feb 2021 ()
En los últimos meses de 2019 —cuando éramos felices y no lo sabíamos—, me encontraba entre dos trabajos. Había dejado mi puesto en Airtable y me estaba preparando para comenzar en Coefficient, la empresa para la que trabajo actualmente como ingeniero de software. La peste todavía no estaba entre nosotros y la escena de música en vivo en Bahía Blanca pasaba por un momento de bastante actividad. Como bajista estable de la Orquesta Congo Bongo y el trío Metatron, yo salía a tocar al menos una vez por semana; una frecuencia bastante alta para un músico amateur en una ciudad chica como Bahía Blanca.
En esa misma época descubrí en Facebook el laburo de Fabio, que publicaba todos los días en su muro una agenda minuciosa de todos los eventos de música en vivo de la ciudad y zona. Como tenía tiempo , me puse en contacto con el y le propuse aunar esfuerzos para sistematizar su laburo e intentar llegar a más personas.
Primer intento
Construí la primer versión de la agenda usando GatsbyJS, un generador de sitios web que en ese entonces gozaba de cierta popularidad. Estuvo online unos días y me di cuenta que no funcionaba para una herramienta de este tipo. Por otro lado, me resultó un horror como sistema: complejo, lento, inestable.
Segundo intento
Seguía teniendo tiempo, así que decidí empezar de vuelta. Esta vez, elegí hacer un sitio con una arquitectura convencional: un frontend implementando con Next.JS y un backend hecho en Python que expone los datos mediante GraphQL.
Para el data entry de los eventos construí un modelo de datos muy simple en Airtable. El backend obtiene los datos periódicamente y los almacena en su base de datos local.
Esta versión se hizo pública a mediados de octubre de 2019. La cosa empezó a tener un crecimiento de tráfico considerable, como se ve en el gráfico. La subida que empieza en Diciembre corresponde con la decisión de haber hecho una Facebook Page, en la que todos los días se publica un posteo que contiene la agenda del día. Esto sucede mediante Zapier, porque usar directamente las APIs de Facebook es exageradamente difícil.

La Gran Cuarentena de 2020
El gráfico anterior es una gran foto del año pasado. A partir de la segunda semana de marzo, la música en vivo desapareció y se desplomó el tráfico a unabanda.org. No tenía sentido seguir trabajando en el sitio, así que pusimos un cartelito y desensillamamos hasta que aclarara.
Tercer nacimiento
Con el fin del invierno 2020, la disminución de casos de COVID-19 y el hartazgo generalizado, volvió timidamente la música en vivo y el incansable Fabio volvió a la carga en su muro de Facebook. Yo tenía ganas de desempolvar a unabanda.org y aproveché para hacer algunos cambios en el sistema.
El frontend quedó igual, pero decidí sacarme de encima el backend que había hecho en Python. Como ya soy programador jovato, quiero escribir la menor cantidad de software posible. En otras palabras, maximizar la funcionalidad minimizando la cantidad de software de la que tengo que hacerme cargo.
Decidí usar Datasette, un proyecto libre y abierto al que le venía siguiendo el rastro hace rato. Simon Willison , su autor, lo define como una multi-herramienta abierta para publicar y explorar datos.
Datasette provee herramientas para acceder a información almacenada en bases de datos SQLite, una herramienta de software que todos usamos aunque no lo sepamos . Simon, además, está construyendo un ecosistema de herramientas alrededor de Datasette. En particular, un plugin que habilita una interfaz GraphQL. Con esto, tenía todas las partes necesarias para reemplazar mi backend con una instancia de Datasette.
Como no hay intenciones comerciales detrás de unabanda.org, el objetivo es usar todos los canales disponibles para difundir la información que compila Fabio. Estamos probando, a partir de este tercer lanzamiento, un canal de Telegram en el que todos los días se publica la agenda.
El frontend de unabanda.org es abierto, publicado bajo la licencia MIT, y su código fuente está disponible en GitHub: https://github.com/jazzido/unabanda.org. El backend (es decir, la instancia de Datasette) también es de libre acceso y está disponible en https://datasette.unabanda.org.
Necesitamos ayuda.
Hacemos unabanda.org porque tenemos ganas de que los recitales exploten de gente. Y para eso, necesitamos de tu ayuda:
Si sos programador/programadora o diseñador/diseñadora, también nos sirve tu ayuda:
- Mejorando el diseño del sitio: lo hice yo, que no soy diseñador. Le pongo la mejor de las ondas, pero está bastante fiero.
- Mejorando el código: no pretendo demasiadas funcionalidad adicionales, pero si se te ocurre algo ponete en contacto conmigo o mandame un pull request.
12 Feb 2021 ()
— Me llamo Manuel y soy adicto a Twitter.
— Hola Manuel.
Hace 13 años conté en este mismo weblog que había abierto una cuenta de Twitter. En ese entonces trabajaba en una de las primeras startups de la web 2.0 argentina. Twitter era cosa de programadores y hipsters. Se caía seguido (era una webapp hecha en Ruby on Rails), no había threads ni @-replies. Mucha gente lo usaba a través de SMS; de ahí el famoso límite de 140 caracteres.
La red social pasó a formar parte de mi vida cotidiana. Fue parte de acontecimientos importantes en mi vida personal y profesional. Me quejé en Twitter cuando en 2011 la gestión Breitenstein en el municipio de Bahía Blanca intentó frenar a Gasto Público Bahiense con un CAPTCHA y se disparó un hermoso escandalete mediático.
En 2012, mientras trabajaba en los inicios de Satellogic, me enteré en Twitter sobre la convocatoria a la fellowship Mozilla-Open News. Me postulé, me entrevistaron, y quedé. Me pasé el 2013 trabajando con medios periodísticos de todo el mundo, viajando a conferencias, y escribiendo software open source. El año siguiente, gracias a esta fellowship, fui aceptado en un programa de posgrado en MIT y nos mudamos a Boston durante 3 años. Ahí nació mi hijo.
Sin Twitter, no hubiera pasado nada de todo eso.
Pero en los últimos años, Twitter empezó a molestarme. Cuando me convocaron para dar mi segunda charla TEDx, hablé de lo mucho que me molestaba. Lo comparé con mi addición a los cigarrillos de tabaco, una comparación que —a diferencia de la charla, que ya no me gusta— me sigue pareciendo acertada.
Venía considerando la idea de eliminar mi presencia en Twitter. Como todos los adictos, me inventaba restricciones para no ir a buscar el colocón: cada tanto borraba todos mis tweets; una operación bastante trabajosa ya que la red no quiere que lo hagas. Le pedía a mi esposa que cambie el password, y unos días después lo recuperaba. Bloqueaba el dominio twitter.com en mi computadora…entonces lo usaba desde el teléfono. Sigue valiendo la analogía tabacalera: dejás de fumar pero pedís una pitada cada tanto, hasta que un día salís a comprar cigarros a las 2 de la mañana.
Pero así como a uno —que ya fuma hace muchos años— le rompe las bolas fumar, Twitter me venía molestando. El medio es el mensaje dijo el tío Marshall, y Twitter es un medio que propicia mensajes horribles: alcahuetería, canchereadas, argumenta ad hominem a cada rato. Superioridad moral: son todos mejor que vos. Y el feedback loop que conocemos todos: posteo mi canchereada y chequeo obsesivamente a ver quién apretó el corazoncito, y me siento premiado por haber sido tan canchero.
Sigamos abusando del argumentum ad tabaci: los ex-fumadores suelen hablar de un momento revelador en el que deciden dejar de fumar. Todavía no tuve ese insight con el cigarro, pero hace unos días lo tuve con Twitter: no me hace falta empezar el día leyendo a cientos de pelotudos con ínfulas de thought leaders alardeando de su ética inquebrantable, sagacidad, elegancia y estado físico. Ni tampoco a presidentes de estados soberanos tuiteando a través de community managers que “entienden la lógica de las redes”. Ni a genios de las finanzas tuiteando desde la casa de sus padres, ni a veganos infumables, ni a les aliades de las cuerpas empoderadas, ni a los machirulos. Todes retuiteando y laiqueándose entre elles, riéndose del contrario via capturas de pantalla con el objetivo de coleccionar corazoncitos.
Le dije a Twitter que sí, que realmente quería borrar la cuenta. Como 12 veces me preguntó.
Igual que el ex-fumador reciente, aquí estoy militando el éxido masivo de ese sitio del infierno. Desde que no paso horas ahí adentro, volví a otras cosas: leo artículos completos,
no soy víctima de tantos trolleos y operaciones burdas. Perdí el movimiento muscular reflejo de abrir un tab del navegador, y abrir Twitter y perder varios minutos. Leo más libros. Toco mi contrabajo y disfruto de no hacer nada.
Todavía estoy en Facebook, porque ahí está la gente que conozco del mundo real, la que me importa de verdad. Y en Instagram, porque soy músico y los músicos están ahí.
Pero Twitter, nunca más.
30 Jan 2021 ()
Heredé de mi abuelo Domingo De Cunto el gusto por el jazz. Cuando nos quedábamos a dormir en su casa, ponía esos casettes con tapa naranja de la colección “Los Grandes del Jazz” de Editorial Sarpe.
Ya adulto, me reencontré con esos casettes, y aprendí que a los 2 años de edad yo ya había escuchado a Coltrane, a Kenton, a Davis, a Getz. Algo me quedó de todo eso, espero.
También heredé del Mingo una pequeña colección de una revista llamada «Jazz Magazine», que se editaba en Buenos Aires en los años 40 y 50. Fueron los años de esplendor del tango, pero el Mingo resistía. Compraba su revista, iba con su Victrola y sus discos, y le hacía escuchar a Armstrong, Ellington y Goodman a todo el mundo. Todavía hoy, a sus 90 años, aprovecha para decirte que el tango es una mierda.
En las páginas de «Jazz Magazine» aparecen crónicas sobre las primeras reuniones del Bop Club Argentino. Hay nombres que aparecían como promesas y hoy son leyenda: Chivo Borraro, Schiffrin, Malvicino, Villegas. Hay reseñas sobre “nuevos lanzamientos” de Parker y Gillespie.
Hace rato que tengo estas revistas. Hoy las escaneé y las subí al Internet Archive, una entidad sin fines de lucro cuya misión es preservar y ofrecer acceso universal al conocimiento de todo el mundo.
27 Jan 2020 ()
La Municipalidad de Bahía Blanca anunció un “sistema online de participación ciudadana”. Opino que es una mala idea, e intentaré explicar por qué.
Cuando opino de política, hablo porque es gratis. Salvo mi interés, y algún que otro libro que he leído, no tengo formación pertinente. Sobre tecnologías aplicadas a la actividad cívica, creo poder hablar con un poco de conocimiento del asunto.
Establezco mis credenciales: por interés personal, hace 10 años construí una herramienta que se llamó Gasto Público Bahiense. Tuvo mucha más repercusión de la que imaginaba, y me llevó por un camino que “terminó” en una maestría en el MIT Media Lab, donde me dediqué a investigar cuestiones relacionadas y construir tecnologías que se inscriben en estas áreas.
Hace 10 años, las tecnologías aplicadas a la participación cívica estaban en auge. Fui partícipe activo y a veces protagonista de esos movimientos durante su máxima popularidad. Participé como disertante y asistente en decenas de conferencias dedicadas al tema en Latinoamérica, Europa y Estados Unidos. Muchas de esas charlas están en YouTube, pueden buscarlas. Fui parte de varios equipos que construyeron “tecnología cívica”. A veces me pagaron, pero casi siempre lo hice ad-honorem y por puro interés profesional.
Me formé como programador de computadoras. Los técnicos solemos pecar de ingenuos cuando, con buena voluntad, ofrecemos desplegar nuestros artilugios en complejas cuestiones socio-políticas. La participación ciudadana es una de esas problemáticas. Durante la inevitable pérdida de inocencia que sufrí en mi devenir en el campo de la tecnología cívica, aprendí que el diseño de una herramienta aplicada a lo sociopolítico es un hecho político. Las computadoras ofrecen una ambigüedad delicada: apagadas, son maquinaria neutral. Encendidas, ejecutan programas que no lo son, pues fueron construídos por seres humanos.
No hablo de fraude o manipulación: casi siempre, esas son cosas de paranoicos (otra clase de inocentes). Aquí, incurrimos en una parcialidad involuntaria. Por ejemplo: ¿quiénes tienen acceso a los dispositivos necesarios para “participar” de manera online? ¿cuáles serán los mecanismos de participación? ¿Quién construyó los sistemas? ¿Serán vinculantes las consultas?
Evgeny Morozov, un autor muy antipático pero que suele ser bastante agudo, habla de “solucionismo”. Es decir, tirarle computadoras a un problema complejo. Esto que parece estar impulsando la Municipalidad —cuando veamos algo concreto intentaré volver a opinar—, es solucionismo de manual. Están tirándole computadoras a un problema que, sospecho, no entienden y no tienen voluntad de entender. Y a juzgar por los productos tecnológicos que construye la Municipalidad, tampoco entienden de computadoras.
La mentada “participación ciudadana” no se activa con un botón, ni con un “Me gusta”. La participación ciudadana se educa, se contruye, se permite. Dudo mucho que la gestión municipal que encabeza Hector Gay (que difícilmente quede en la historia por su vocación democrática y participativa) sea capaz de llevar adelante un proyecto de estas características.
Hoy ya no participo de los movimientos de Datos Abiertos y Gobierno Abierto. Descubrí que no tengo ni me interesa desarrollar el el temple necesario para lidiar con el sector público. Pero habité ese campo durante una parte importante de mi carrera profesional, por ende sigo el tema con interés.
En la cancha se verán los pingos. No obstante, habiendo visto varias de estas iniciativas en Argentina y en todo el mundo, es muy probable que esto que el Municipio anuncia con bombos, platillos y pocos detalles, desaparezca en muy poco tiempo.
27 May 2019 ()
Lo siguiente es un ejercicio de análisis de un dataset de reproducciones emitido por el servicio Distrokid, para un artista argentino con 2.5 millones de reproducciones en los últimos 9 meses, en el servicio de streaming Spotify.
import pandas as pd
import altair as alt
import numpy as np
data = pd.read_csv('DistroKid_1558988581759.tsv', sep='\t', encoding='iso-8859-1')
sales = data[(data.Store == 'Spotify')]
Las columnas que nos interesan son:
Store: sólo vamos a considerar SpotifyQuantity: la cantidad de streams que se reportan en esta filaCountry of Sale: El país en el que fue escuchado el streamEarnings (USD): lo pagado para la cantidad de streams reportada en esta fila. Asumimos que el pago por un stream es Earnings (USD)/Quantity
Ingreso mensual
sales_per_month=sales.groupby(['Sale Month'])[['Quantity', 'Earnings (USD)']].sum().reset_index()
alt.Chart(sales_per_month).mark_bar().encode(
x='Sale Month:O',
y='Earnings (USD):Q',
tooltip='Quantity:Q',
).properties(width=500, title="Ingreso (USD) por mes")\
.configure(background='#FFFFFF')
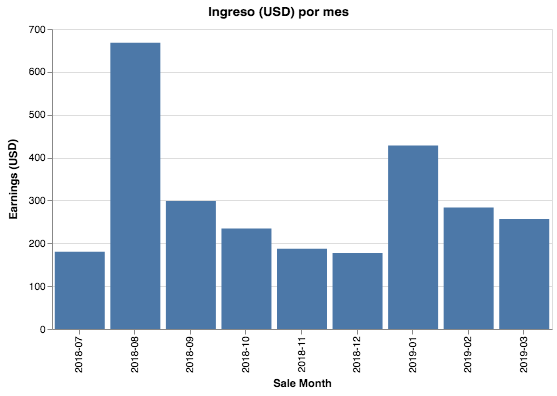
Los meses de aumento en el ingreso corresponden a lanzamientos.
¿En qué países está la audiencia?
Por supuesto, nos interesa saber a dónde está la mayor cantidad de escuchas de nuestros tracks
by_country = sales.groupby('Country of Sale').sum().reset_index()
top_10_countries = by_country.sort_values('Quantity', ascending=False).head(10).reset_index()
top_10_countries[['Country of Sale', 'Quantity']]
|
Country of Sale |
Quantity |
| 0 |
AR |
1917972 |
| 1 |
CL |
199124 |
| 2 |
UY |
98114 |
| 3 |
US |
37505 |
| 4 |
PE |
31865 |
| 5 |
MX |
30346 |
| 6 |
CO |
14393 |
| 7 |
ES |
12948 |
| 8 |
PY |
10372 |
| 9 |
EC |
9856 |
Vemos que Argentina es el país principal, muy por encima del resto de los países: un orden de magnitud superior al segundo puesto. Graficamos esta distribución en un gráfico con escala logarítmica en el eje vertical.
(Ya que estamos,agregamos las banderas de los países)
OFFSET = ord('🇦') - ord('A')
def flag(code):
""" Retorna el emoji de la bandera de un país, dado su código ISO-3166 alpha-2"""
return chr(ord(code[0]) + OFFSET) + chr(ord(code[1]) + OFFSET)
top_quantity = by_country.sort_values('Quantity', ascending=False).reset_index()
top_quantity.loc[:, 'country_name_and_flag'] = top_quantity['Country of Sale'].apply(lambda c: flag(c) + c)
alt.Chart(top_quantity.sort_values('Quantity', ascending=False)).mark_bar().encode(
x=alt.X('country_name_and_flag:N', sort=list(top_quantity['country_name_and_flag'])),
y=alt.Y('Quantity:Q',scale=alt.Scale(type='log')),
).properties(
title='Number of streams per country (log scale)',
)\
.configure(background='#FFFFFF')
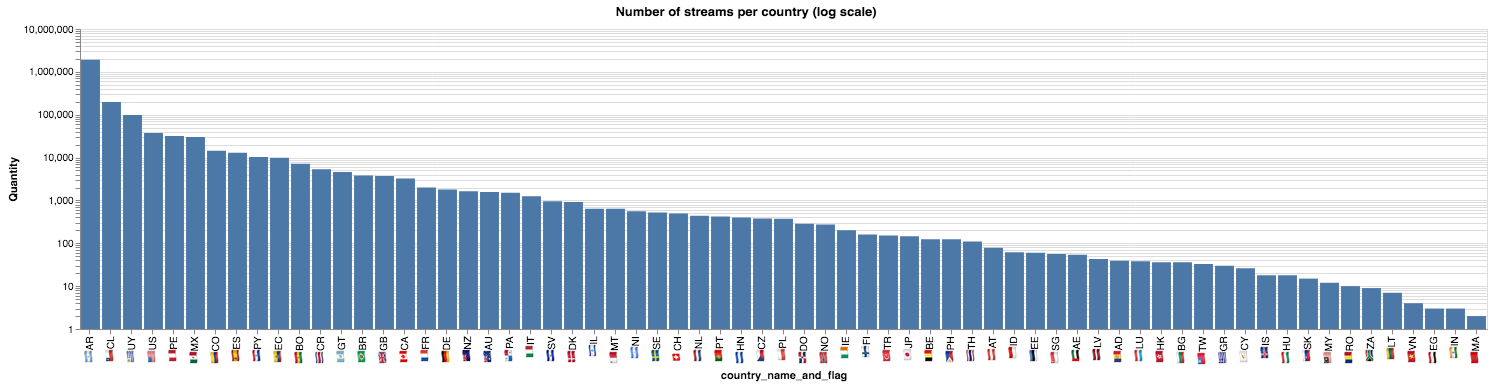
Promedio de pago por stream en cada país
Intentaremos, de manera muy poco rigurosa, estudiar la relación entre el importe promedio que Spotify paga al artista por cada reproducción, y el costo de la suscripción mensual en cada país.
Comenzamos calculando el valor promedio de cada reproducción (stream)
metrics = by_country[['Country of Sale', 'Quantity', 'Earnings (USD)']].sort_values('Quantity', ascending=False)
metrics = metrics.assign(per_stream_avg=metrics['Earnings (USD)']/metrics['Quantity'])
metrics[['Country of Sale', 'Quantity', 'per_stream_avg']].head(10)
|
Country of Sale |
Quantity |
per_stream_avg |
| 2 |
AR |
1917972 |
0.000965 |
| 11 |
CL |
199124 |
0.001405 |
| 64 |
UY |
98114 |
0.002186 |
| 63 |
US |
37505 |
0.002802 |
| 50 |
PE |
31865 |
0.001511 |
| 43 |
MX |
30346 |
0.001261 |
| 12 |
CO |
14393 |
0.001187 |
| 22 |
ES |
12948 |
0.002075 |
| 54 |
PY |
10372 |
0.001203 |
| 19 |
EC |
9856 |
0.001744 |
Graficamos el promedio por reproducción para cada país
top_per_stream_avg = metrics.sort_values('per_stream_avg', ascending=False)
top_per_stream_avg.loc[:, 'country_name_and_flag'] = top_per_stream_avg['Country of Sale'].apply(lambda c: flag(c) + c)
alt.Chart(top_per_stream_avg).mark_bar().encode(
x=alt.X('country_name_and_flag:N', type='nominal', sort=list(top_per_stream_avg['country_name_and_flag'])),
y='per_stream_avg:Q',
tooltip=['per_stream_avg:Q']
).properties(
title='Per-stream payout average by Country\n(from a Spotify royalties report with %.2fM plays)' % (metrics.Quantity.sum() / 1e6)
)\
.configure(background='#FFFFFF')
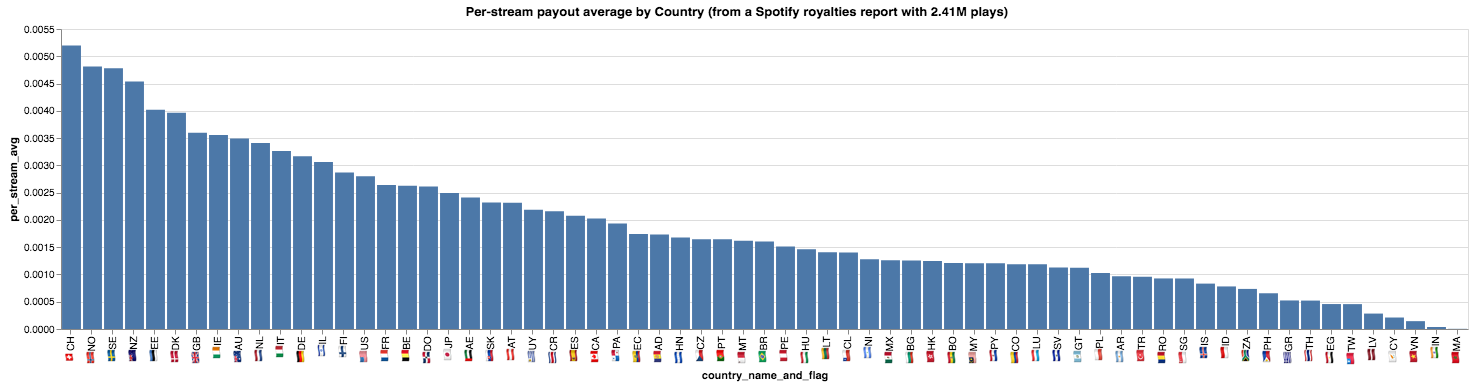
Suiza (CH) es el país que “mejor” paga por cada reproducción ($0.005 USD). Vemos también que los países en el tope del ranking pertecen al hemisferio norte. Gana peso nuestra hipótesis de que el per-stream average payout está relacionado con el costo de la suscripción al servicio Spotify
Costo mensual de Spotify en cada país
Necesitamos, por supuesto, una base de datos que contenga el costo de la suscripción a Spotify en cada país. Pensé en scrapearlo, pero por suerte un señor danés llamado Matias Singer construyó un Spotify International Pricing Index que contiene la información que necesitamos.
Los datos en la versión publicada están muy desactualizados, pero el buen Matias publicó el código fuente del scraper. Luego de unas modificaciones triviales, ejecuté ese código y obtuve la data que necesitaba.
spotify_monthly = pd.read_json('./spotify-pricing.jsonlines', lines=True)
spotify_monthly = spotify_monthly[spotify_monthly.convertedPrice > 0]
spotify_monthly.loc[:, 'country_upper'] = spotify_monthly.rel.str.upper()
spotify_monthly.head(5)
|
convertedPrice |
countryCode |
currency |
demonym |
internationalName |
link |
originalCurrency |
originalPrice |
originalRel |
price |
region |
rel |
subRegion |
title |
country_upper |
| 0 |
4.990000 |
DZA |
DZD |
Algerian |
Algeria |
/dz-fr/premium/?checkout=false |
DZD |
USD 4.99/mois |
dz-fr |
4.99 |
Africa |
dz |
Northern Africa |
Algérie (français) |
DZ |
| 1 |
7.506266 |
CAN |
CAD |
Canadian |
Canada |
/ca-fr/premium/?checkout=false |
CAD |
9,99 $ CAD/mois |
ca-fr |
9.99 |
Americas |
ca |
Northern America |
Canada (français) |
CA |
| 2 |
5.990000 |
GTM |
GTQ |
Guatemalan |
Guatemala |
/gt/premium/?checkout=false |
GTQ |
5.99 USD al mes |
gt |
5.99 |
Americas |
gt |
Central America |
Guatemala |
GT |
| 3 |
5.990000 |
ECU |
USD |
Ecuadorean |
Ecuador |
/ec/premium/?checkout=false |
USD |
5.99 USD al mes |
ec |
5.99 |
Americas |
ec |
South America |
Ecuador |
EC |
| 4 |
7.506266 |
CAN |
CAD |
Canadian |
Canada |
/ca-en/premium/?checkout=false |
CAD |
$9.99 CAD / month |
ca-en |
9.99 |
Americas |
ca |
Northern America |
Canada (English) |
CA |
Vamos a visualizar en un scatterplot las dos variables que nos interesan, valor promedio por reproducción y costo mensual del servicio.
El eje horizontal codificará el per-stream average payout, mientras que el vertical el costo mensual de la suscripción. El color de cada punto corresponde a la región del país, mientras que el tamaño codifica la cantidad de reproducciones.
Combinamos (merge) nuestro dataset de pago promedio por reproducción con el dataset obtenido por el scrapper, y construímos el scatterplot.
stream_avg_monthly_scatter = top_per_stream_avg.merge(spotify_monthly, left_on='Country of Sale', right_on='country_upper')
stream_avg_monthly_scatter.loc[:, 'convertedPriceFit'] = pd.Series(np.poly1d(fit)(stream_avg_monthly_scatter.per_stream_avg))
scatter = alt.Chart(stream_avg_monthly_scatter).mark_circle().encode(
x='per_stream_avg:Q',
y='convertedPrice:Q',
tooltip=['internationalName:N', 'convertedPrice:Q', 'per_stream_avg:Q', 'Quantity:Q'],
color='region:N',
size=alt.Size('Quantity:Q', scale=alt.Scale(range=(50,1000))),
).properties(
title="Per-stream AVG payout VS Spotify monthly price by country (R²=%.2f)" % fit_rsq
)\
.configure(background='#FFFFFF')
scatter
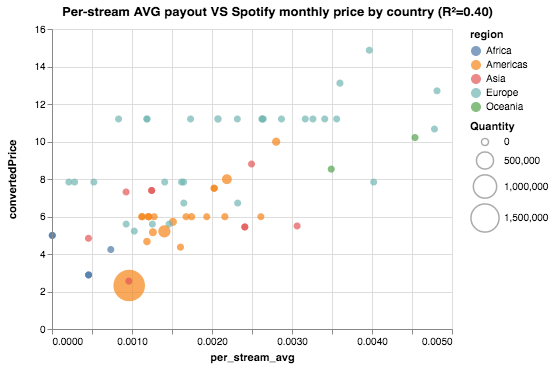
Vemos un atisbo de correlación lineal entre las dos variables. También vemos agrupaciones “horizontales”, que corresponden a importes como $5.99 (psychological pricing). Calculamos un fit lineal y también lo graficamos. También vamos a agregar líneas horizontales para enfatizar los países que comparten importes.
fit = np.polyfit(stream_avg_monthly_scatter.per_stream_avg, stream_avg_monthly_scatter.convertedPrice, 1)
fit_rsq = np.corrcoef(stream_avg_monthly_scatter.per_stream_avg, stream_avg_monthly_scatter.convertedPrice)[0,1]**2
scatter = alt.Chart(stream_avg_monthly_scatter).mark_circle().encode(
x='per_stream_avg:Q',
y='convertedPrice:Q',
tooltip=['internationalName:N', 'convertedPrice:Q', 'per_stream_avg:Q', 'Quantity:Q'],
color='region:N',
size=alt.Size('Quantity:Q', scale=alt.Scale(range=(50,1000))),
).properties(
title="Per-stream AVG payout VS Spotify monthly price by country (R²=%.2f)" % fit_rsq
)
linear_fit = alt.Chart(stream_avg_monthly_scatter).mark_line().encode(
x='per_stream_avg:Q',
y='convertedPriceFit:Q'
)
# add fixed price points
fixed_price_points = pd.DataFrame(
[
{'text': '9.99€', 'rule': 11.20},
{'text': '6.99€', 'rule': 7.83},
{'text': '$5.99', 'rule': 5.99}
]
)
fixed_price_rules = alt.Chart(fixed_price_points).mark_rule(strokeDash=[1,1]).encode(
y='rule:Q',
)
fixed_price_text = alt.Chart(fixed_price_points).mark_text(align='left', dy=-5, dx=5).encode(
text='text:N',
y='rule:Q',
x=alt.X(value=0)
)
(scatter + linear_fit + fixed_price_rules + fixed_price_text).configure(background='#FFFFFF')
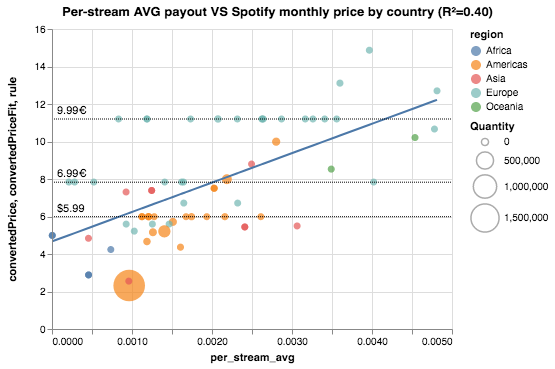
Qué averiguamos?
El resultado de este ejercicio informal y superficial sugiere que hay una relación entre el costo de la suscripción mensual al servicio Spotify, y lo que pagan a los artistas en concepto de royalties. También, el dato curioso de que Argentina es el país con el costo de suscripción más barato del mundo.
Si la relación que investigamos existe en efecto, podemos decir que pegar un hit en Argentina es un mal negocio en comparación al resto de los países.