Matrices y nombres
12 Aug 2017Esta semana, la Dirección Nacional de Datos e Información Pública publicó “Tu nombre en los últimos 100 años”, un sitio muy divertido que permite consultar frecuencias de uso de nombres propios. Parecido al Popular Baby Names de la Social Security Administration de Estados Unidos. Junto con el sitio, el equipo de datos públicos subió el dataset al portal de datos públicos.
El diario La Nación publicó un enlace al sitio de nombres en su home page…y se vino abajo por el tráfico.
Para poner a andar un ratito la croqueta, me puse a pensar cómo hacer un método eficiente de consulta de esta información. Dado uno o varios nombres, quiero obtener la serie temporal de sus frecuencias. No es nada del otro mundo, y es apenas un prototipo.
Preparando el dataset
cat historico-nombres.csv | uconv -t ASCII -x nfd -c | tr '[:upper:]' '[:lower:]' | tr -s ' ' | sed -e 's/^ *//' -e 's/ *$//' | csvfix sort -smq -rh -f 1:S,3:N > sorted-ascii-historico-nombres.csv
Ese pipeline de comandos procesa el archivo original aplicando las siguientes transformaciones:
uconv -t ASCII -x nfd -c: Aplicar la forma de normalización Canonical Decomposition de Unicode (NFD). En criollo, sacarle acentos a los caracterestr '[:upper:]' '[:lower:]': pasar todo a minísculastr -s ' ': convertir espacios repetidos a uno sólo.sed -e 's/^ *//' -e 's/ *$//': sacar espacios del principio y final de cada línea.csvfix sort -smq -rh -f 1:S,3:N: ordenar la tabla según nombre y luego año.
Nos queda algo así:
| nombre | cantidad | anio |
|---|---|---|
| aage tomasen | 2 | 1931 |
| aago peter | 1 | 1987 |
| aakash | 2 | 1985 |
| aalam yamir | 2 | 2013 |
| aale rene | 1 | 1987 |
| aalejandro daniel | 1 | 2002 |
| aaleyah nayara | 2 | 2013 |
Una estructura eficiente
Lo más simple que se me ocurrió es pivotear ese dataset, para convertirlo en una matriz donde cada fila es un nombre y cada columna es un año. Tenemos 3044402 nombres únicos y un período de 94 años. Es decir, una matriz de 3044402 x 94.
Para poder obtener la fila correspondiente al nombre que nos interesa, también construimos un diccionario NAMES cuyas claves son los nombres y sus valores el índice de la fila de la matriz que contiene la serie temporal de frecuencias.
El siguiente script construye esas estructuras de datos.
# coding: utf-8
import csv, sys, pickle
import numpy as np
YEAR_MIN, YEAR_MAX = 1922, 2015
YEARS_Q = YEAR_MAX - YEAR_MIN
NAMES_Q = 3044402 # count-distinct on the name column
NAMES = {}
FREQS = np.zeros((NAMES_Q, YEARS_Q+1), int)
reader = csv.reader(sys.stdin)
next(reader) # skip header
# Pivotear el dataset de nombres:
# a partir de una tabla de (nombre, frecuencia, año), construir una matriz
# de frecuencias |nobmres| x |años|
cur_name, cur_row, i = None, None, -1
for row in reader:
if row[0] != cur_name:
i += 1
NAMES[row[0]] = i
if i % 2000 == 0:
print("%d names processed" % i)
FREQS[i, int(row[2]) - YEAR_MIN] += int(row[1])
cur_name = row[0]
# save FREQS
np.save('freqs', FREQS)
# save NAMES
with open('names.pickle', 'wb') as f:
pickle.dump(NAMES, f)
Consultando las frecuencias
Cómo consultamos esto? Fácil. Obtenemos el índice del nombre que nos interesa, y con él, la fila correspondiente en la matriz:
import numpy as np
import pickle
FREQS = np.load('freqs.npy')
with open('names.pickle', 'rb') as f:
NAMES = pickle.load(f)
FREQS[NAMES['manuel']]
array([ 56, 2, 119, 122, 2, 1, 4, 231, 6, 2, 326,
268, 330, 1, 330, 332, 6, 356, 3, 3, 4, 2,
3, 494, 464, 510, 8, 4, 1, 365, 374, 3, 317,
3, 3, 308, 3, 253, 8, 5, 1, 1, 1, 180,
167, 3, 161, 151, 193, 156, 144, 173, 5, 223, 269,
4, 242, 2, 3, 238, 268, 8, 1, 436, 456, 415,
487, 458, 566, 627, 555, 801, 1013, 1135, 1012, 783, 786,
760, 729, 678, 736, 815, 2, 0, 718, 726, 705, 650,
581, 600, 814, 789, 849, 711])
Visualizamos el resultado para verificar que al menos se parezca a lo que reporta el sitio oficial. Para esto, también vamos a calcular el pormilaje (?) del nombre de interés para cada año. Con los datos en esta matriz, es fácil: la cantidad de nombres en cada año es la suma de cada columna.
manuel_1000ct = (FREQS[NAMES['manuel']] / np.sum(FREQS, axis=0)) * 1000
from altair import Chart, Bin, X, Axis
import pandas as pd
data = pd.DataFrame({'year': list(range(1922,2016)), 'freq': manuel_1000ct})
chart = Chart(data).mark_line().encode(
x='year:N',
y='freq:Q',
)
chart
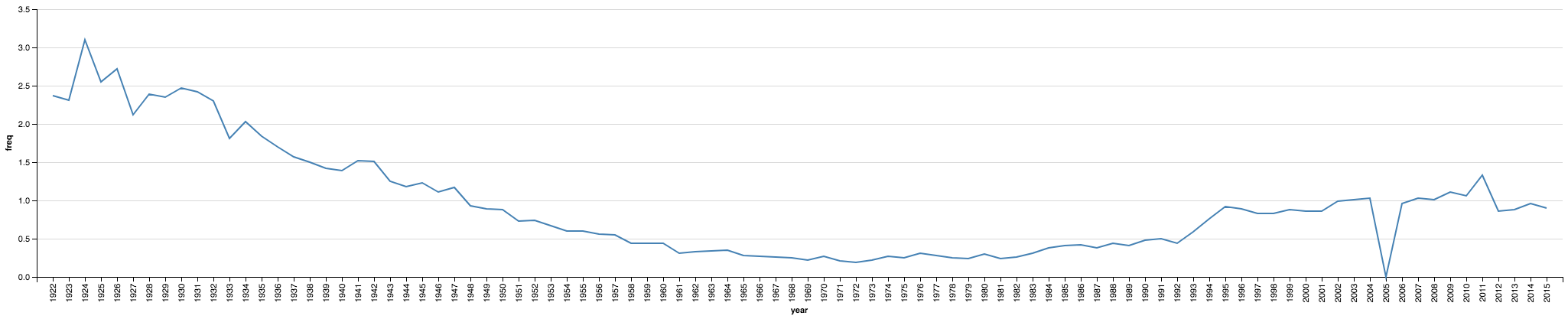
Es parecido, pero no igual 😔. El 0 en 2005 no coincide con la fuente, sospecho algun problema de comparacion de strings.
Mirá, mamá: sin base de datos.
El tamaño de la matriz FREQS es relativamente chico, apenas 2.13 gigabytes en memoria.
FREQS.nbytes / 1024**3
2.132160872220993
El diccionario de nombres (NAMES) tampoco ocupa mucho; 160 megabytes.
sys.getsizeof(NAMES) / 1024**2
160.0000991821289
Este pequeño ejercicio se puede exponer a través de un endpoint HTTP muy simple que mantenga esta matriz numpy en memoria y envíe los datos serializados en la respuesta.
Con eso, estimo, se pueden mejorar bastante la estabilidad y robustez del servicio
[El código está disponible aquí: https://gist.github.com/jazzido/1050fd9169adb7fd9ff1d1002649fd16]