26 Oct 2014 (1 Comment)
Hace un tiempo, la ciudad de Bahía Blanca introdujo tarjetas de proximidad para el pago de la tarifa del servicio de transporte público. Junto con el sistema AVL con el que cuentan las unidades, los registros de uso de las tarjetas de proximidad son una fuente de información valiosa.
Como excusa para aprender un poco más sobre IPython Notebook, matplotlib y Basemap, estuve jugando con aproximadamente 4.3 millones de registros del sistema de transporte público bahiense, puestos a disposición por la Agencia de Innovación y Gobierno Abierto de la ciudad.
El notebook completo se puede ver acá: Datos de Automated Fare Collection del sistema de transporte público de Bahía Blanca
Los campos más importantes de los registros sobre los que trabajamos son:
- Fecha y Hora — momento en que se registró la transacción
- ID tarjeta — identificador numérico, único y no vinculable con los datos personales del usuario
- Línea Ómnibus — Línea (servicio) de ómnibus
- Locación — Lectura del GPS de la unidad al momento de realizarse la transacción
- Tipo Pasaje — Normal, frecuente, escolar, etc.
Una vez procesados y guardados en una tabla de una base de datos PostgreSQL/PostGIS, podemos empezar a hacer algunos análisis simples.
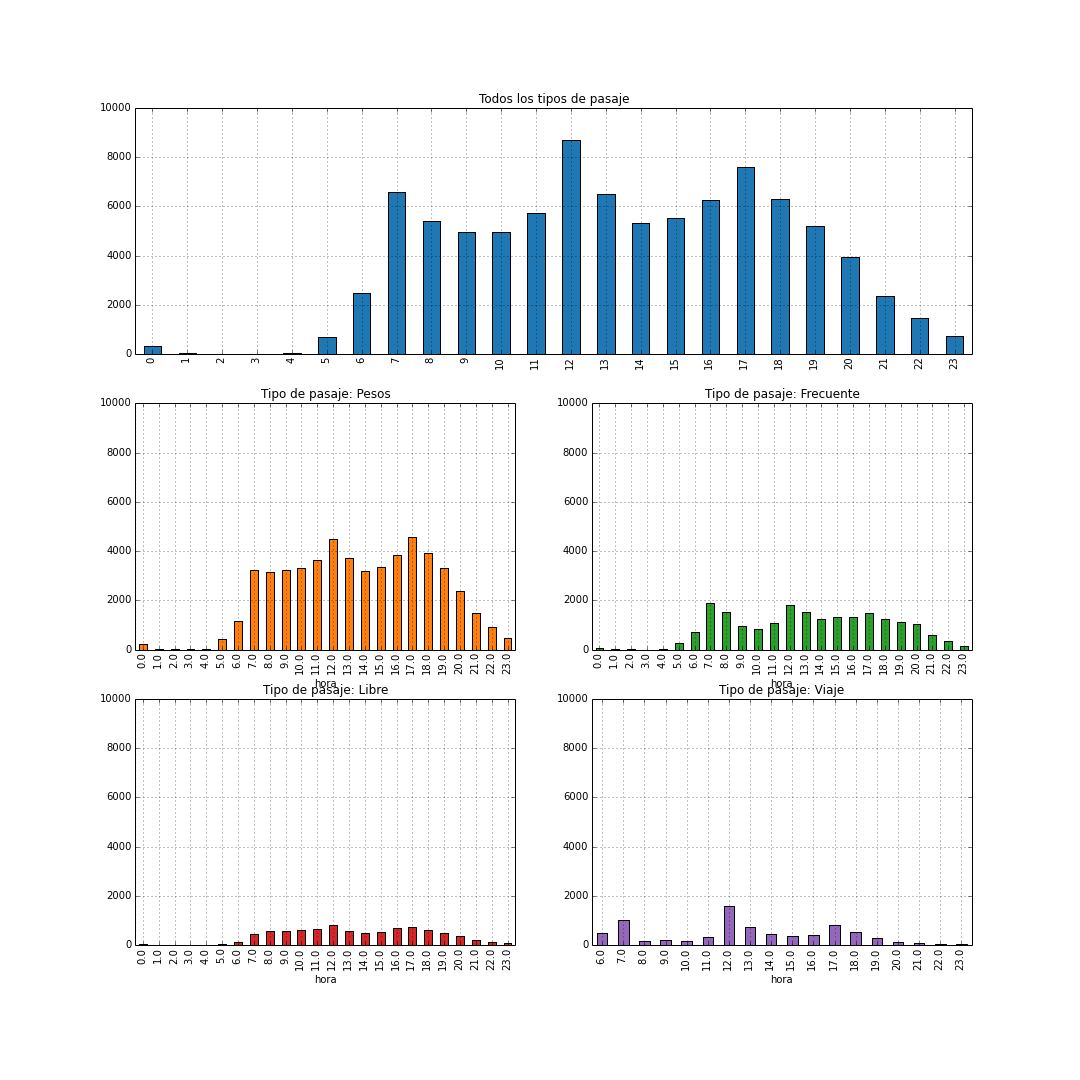
Promedio de viajes por hora
Podemos ver, por ejemplo, la cantidad promedio de viajes efectuados en cada hora del día para los días hábiles de la semana. El pico de actividad en el mediodía, quizás se deba al horario comercial “cortado” que se acostumbra en Bahía Blanca y otras ciudades del interior.
“Perfil” de usuario.
Es razonable considerar análisis que requieran tipificar usuarios en base a sus patrones de uso. Una posible forma de construir estos perfiles es la siguiente:
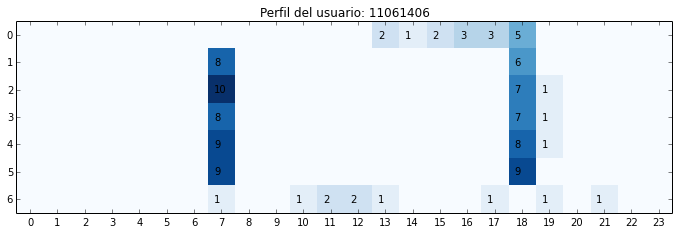
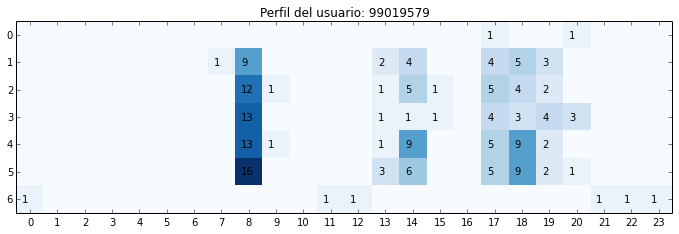
Los gráficos muestran la cantidad de viajes por hora y día de la semana para un período determinado. En el primero vemos uso consistente alrededor de las 7 de la mañana y de las 6 de la tarde.
Viajes encadenados
Nos interesa ver las combinaciones más frecuentes de dos líneas de ómnibus. Esta estadística puede indicarnos qué áreas de la ciudad no están bien conectadas por una única línea.
Decimos que los viajes v1 y v2 del pasajero p están encadenados si:
- La diferencia de tiempo entre v2 y v1 es menor a 45 minutos
- v1 y v2 fueron realizados en diferentes líneas (o sea, no consideramos viajes de retorno hacia el punto de partida)
Graficamos la matriz de combinaciones de líneas de omnibus:
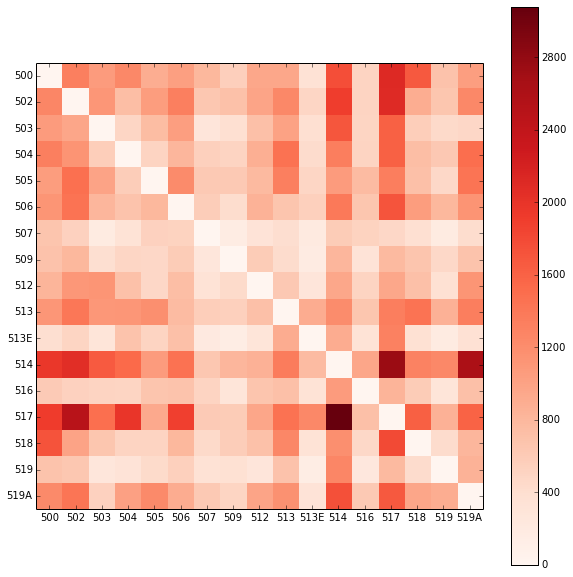
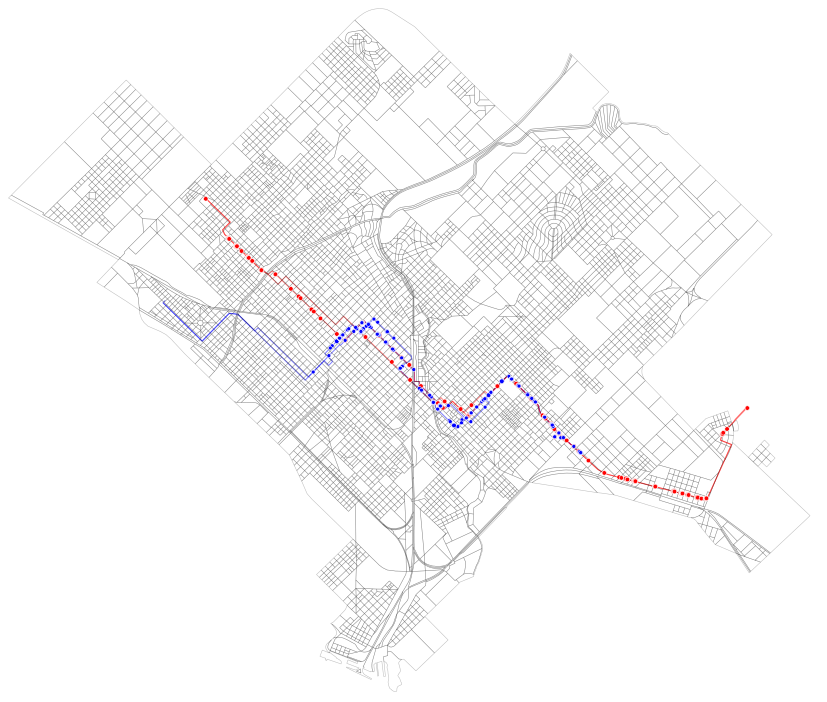
También es interesante ver dónde comienzan sus viajes los usuarios que realizan la combinación 514-517, una de las más frecuentes:
04 Jun 2014 (2 Comments)
La metáfora surgió en el ya legendario primer hackatón de información pública que organizamos en GarageLab hace casi 4 años: así como el software suele informar su actividad en un log, el estado hace lo mismo a través de los boletines oficiales que publica diariamente. La versión del estado nacional estuvo dividida históricamente en tres secciones: Legislación y avisos oficiales, sociedades, contrataciones. Hace pocas semanas se incorporó una cuarta sección, donde se publican los nuevos nombres de dominio registrados a través de NIC.ar.
Desde GarageLab experimentamos con el problema de recuperar, estructurar y analizar la información contenida en las primeras 3 secciones del Boletín. Durante la edición 2011 de Desarrollando América Latina, los miembros de Banquito desarrollaron un prototipo de scraper e interfaz de consulta para la tercera sección, mientras que Damián Janowski y yo trabajamos en un prototipo de scraper y named entity recognizer para la sección de sociedades.
En preparación para el hackatón panamericano La Ruta del Dinero que se va a hacer este sábado 7 de junio de 2014, retomé las ideas con las que estuvimos jugando hace unos años. La composición de los directorios, novedades, quiebras y edictos de las empresas registradas en el país son una fuente de información importante para seguir la ruta del dinero.
boletinoficial.gov.ar
Además de ser publicado en papel y en PDF, el Boletín Oficial tiene un sitio web que publica la información de manera más o menos estructurada. Su usabilidad y performance dejan bastante que desear, pero es bastante fácil de scrapear gracias a que las páginas se generar a partir de un servicio que emite documentos XML (Ver ejemplo)
Es decir, el sistema que publica el Boletín en la web, almacena los datos estructurados pero no nos ofrece la posiblidad de obtenerlos de esa manera.
Entonces hay que scrapear
Publiqué en GitHub un script en Python que obtiene los avisos de la segunda sección para una fecha dada y emite un archivo CSV: https://github.com/jazzido/boscrap.
Para usarlo, bajar el contenido del repositorio, instalar las dependencias con pip install -r requirements.txt y ejecutar:
python boscrap.py 2014-06-04
09 May 2014 (49 Comments)
ACTUALIZACIÓN 9 de Junio de 2015: INDEC publicó mapas de todas las provincias een formato SHP que contienen la división censal por radios. El siguiente post se mantendrá por razones históricas, pero recomiendo usar la fuente oficial disponible aquí: http://www.indec.gov.ar/codgeo.asp
Como a todos los que trabajan con información pública, me interesa conseguir datos al menor nivel de agregación posible. Para decirlo de otro modo, en alta definición. Esa fue la idea detrás del mapa de resultados electorales a nivel de centro de votación que hice el año pasado en LaNacion.com, como becario Knight-Mozilla OpenNews. El primer proyecto que desarrollé durante esa beca, fue una visualización interactiva de los datos arrojados por los dos últimos censos de población en Argentina. El plan original para ese proyecto también era mostrar los datos al menor nivel de agregación posible que para el censo son los radios censales, definidos como una porción del espacio geográfico que contiene en promedio 300 viviendas. Por desgracia, no estaban disponibles los mapas que definen los radios, ni los datos de las variables censales a ese nivel.
Los radios censales son partes de una fracción censal, que están a su vez contenidas en los departamentos o partidos, el segundo nivel de división administrativa en Argentina. Hoy es posible disponer de los datos del último censo a nivel de radio censal. Cabe destacar que no fueron publicados oficialmente, sino que aparecieron en el tracker de BitTorrent The Pirate Bay (!). Fueron publicados dentro de una aplicación basada en el sistema REDATAM y en febrero pasado convertí esas tablas a un formato más universal. Notar que es necesario el uso de REDATAM para análisis tales como tabulaciones cruzadas (tablas de contingencia). Por ejemplo, universitarios que tienen acceso a internet por fracción censal en la provincia x.
La otra pieza del rompecabezas
Por supuesto, para visualizar estos resultados nos hacen falta las descripciones geográficas de las fracciones y radios censales. A partir de los datos del censo, podemos acceder a todas las variables —por ejemplo— del radio 300080111 y sabemos que está en la localidad de Colón de la provincia de Entre Ríos, pero no conocemos sus límites exactos. Sólo la provincia de Buenos Aires y la Ciudad Autónoma de Buenos Aires publican cartografía censal en formatos estándar. El INDEC mantiene un sitio informativo sobre “unidades geoestadísticas” en el que publica información geográfica hasta el nivel de radio censal (en formato SVG) pero desprovista de georeferenciación. Es decir, podemos obtener la geometría de cualquier provincia, departamento/partido, fracción o radio censal pero no está asociada al espacio físico. Este post describirá un método de georeferenciación de esos gráficos vectoriales, usando otro mapa publicado por INDEC como referencia.
¿Cómo se scrapea un mapa?
Podemos definir scraping como un proceso en el que recojemos información no estructurada y la ajustamos a un esquema predefinido. Por ejemplo, un scraper de resultados de búsqueda de Google que los almacene en una base de datos estructurada. Para este experimento, vamos a llevar a cabo un procedimiento análogo, pero aplicado a mapas. Es decir, vamos a tomar gráficos vectoriales no-georeferenciados del sitio de unidades geoestadísticas de INDEC y vamos a ajustarlo a una proyección geográfica (POSGAR 94 Argentina 3).
Malabares vectoriales
Los gráficos publicados en el nivel “departamento” de los SVG de INDEC son un gráfico vectorial de un partido/departamento que contiene fracciones, que son el siguiente nivel en la jerarquía de unidades geoestadísticas:

En el gráfico de arriba, vemos los límites del partido de Bahía Blanca y sus divisiones internas (fracciones).
Aunque INDEC no publica las unidades geoestadísticas de menor nivel en un formato georeferenciado, sí pone a disposición un mapa de departamentos tal como fueron considerados para el último censo. Ese mapa será nuestra referencia para georeferenciar los SVGs ya mencionados.
Para eso, vamos a tomar los puntos extremos (extremos de la envolvente) de un partido tal como fue publicado en el SVG y del mismo partido tal como fue publicado en el mapa de departamentos, que sí está georeferenciado:

Los puntos del mapa de la derecha están georeferenciados, y “sabemos” (asumimos, en realidad) que se corresponden con los puntos del de la izquierda. Con ese par de conjuntos de puntos, podemos calcular una transformación tal que convierta los vectores no-georeferenciados al espacio de coordenadas del mapa georeferenciado. Para eso, vamos a usar el módulo transform de la librería scikit-image. Aclaremos cuanto antes, para que no se ofendan los cartógrafos y geómetras: este procedimiento es muy poco formal (se muy poco de cartografía y de geometría) y poco preciso (el SVG está muy simplificado con respecto al mapa original).
Aplicando esa transformación a todas las fracciones contenidas en el departamento, y procediendo de manera análoga para el siguiente nivel geoestadístico (radios), vamos a obtener una aproximación bastante burda a un mapa de fracciones y radios censales.
Implementación
El procedimiento, que se ha descripto de manera muy resumida, está implementado en el programa georef_svg.py. Para correrlo hay que instalar las dependencias listadas en requirements.txt y bajar los SVGs del sitio de INDEC. Para eso, se provee el script source_svg/download.sh. Ejecutando python georef_svg.py ., obtendremos dos shapefiles fracciones.shp y radios.shp, que contienen el resultado del proceso. Un ejemplo del resultado de este proceso se incluye en el directorio output_shp.
El resultado no debe ser considerado como un mapa usable de fracciones y radios, dadas las imprecisiones y errores que contiene. En el mejor de los casos, quizás pueda ser un punto de partida para la confección de un mapa apropiado…hasta que INDEC (o quien corresponda) publique la información en un formato geográfico estándar.
17 Mar 2014 (0 Comments)
Hoy, por Twitter, me enviaron un link a la información sobre “fondos públicos destinados a la difusión de actos de gobierno” que publica la Jefatura de Gabinete. En formato PDF, como no podía ser de otra manera. Cada vez que aparece un PDF con una tabla adentro pruebo si Tabula (la aplicación que estoy desarrollando desde el año pasado) es capaz de extraerla. Funcionó casi perfectamente y luego de un poco de data cleansing, la información estuvo lista para ser analizada. La Jefatura de Gabinete publica semestralmente un detalle de gasto publicitario: por organismo y rubro, y por proveedor y rubro. El último conjunto de datos disponible corresponde al primer semestre del año 2013. En sendos Google Spreadsheets, republiqué datos extraídos de los PDFs:
24 Feb 2014 (90 Comments)
Los censos de población son uno de los conjuntos de datos fundamentales que produce el Estado. En Argentina, el último Censo Nacional de Población, Hogares y Viviendas se realizó el día 27 de octubre de 2010. Más de 3 años después, aparecieron en la web los resultados del cuestionario básico, desagregados a nivel de radio censal (la división espacial más chica en la que se publica el censo) y publicados en forma de una aplicación Windows desarrollada en base al sistema REDATAM
¿Qué es REDATAM?
Como muchos institutos nacionales de estadística, el INDEC usa el programa REDATAM para la confección y publicación de la base de datos de resultados censales. Este sistema es desarrollado por el CELADE, dependiente de la Comisión Económica para América Latina y el Caribe.
Considerando su adopción por numerosos organismos gubernamentales y el prestigio de sus responsables, no dudo de la alta calidad del sistema. No obstante, como bien señaló Andrés Vázquez en su blog, REDATAM presenta algunas complicaciones a la hora de reutilizar los datos con las herramientas, prácticas y convenciones a las que nos hemos acostumbrado en los últimos años. Llama la atención, además, que no estén públicamente disponibles ni su código fuente, ni la especificación de los formatos que utiliza para almacenar la información.
REDATAM es una aplicación con interfaz gráfica de usuario, pero también incluye un “procesador estadístico” (R+SP Process) que permite definir y exportar tablas mediante programas escritos en un lenguaje propio del sistema. Dado el diccionario de variables y entidades almacenadas en REDATAM, es posible construir consultas que exporten todas las variables a un archivo para luego convertirlo a un formato abierto que facilite su reutilización.
Liberando la información
Publiqué en GitHub un conjunto de scripts en lenguaje Python, que generan las queries apropiadas para ser ejecutadas por REDATAM y exportar casi todas las variables a DBF. Estos últimos son luego convertidos a archivos CSV (valores separados por comas). También publiqué los resultados de este procesamiento.
Cabe aclarar que estos archivos no son una fuente oficial de información y no asumo ninguna responsabilidad sobre su uso.. Las consultas generadas funcionan únicamente para los datos mencionados antes, pero es posible que esta metodología sea aplicable a otras bases de información publicadas con REDATAM.
¿Dónde están los radios censales?
Los radios censales —contenidos en las fracciones *censales— son una división administrativa del espacio. Su tamaño está definido por la cantidad de viviendas que contienen: una fracción censal contiene un promedio de 5000 viviendas y un radio contiene un promedio de 300 (fuente). Sólo la provincia de Buenos Aires y la Ciudad Autónoma de Buenos Aires publican la definición de estas divisiones en formatos geográficos apropiados. El INDEC mantiene un sitio informativo sobre “Unidades Geoestadísticas” para todo el país, pero publica los polígonos de los radios y fracciones censales en forma de archivos SVG desprovistos de información geográfica (imprescindible para *georeferenciar los datos)
Un ejemplo
Creo que visualizar información pública en “alta resolución” es valioso. El año pasado, como becario del programa OpenNews en el diario La Nación, participé en el desarrollo de una infografía interactiva sobre los resultados de las elecciones legislativas que introdujo la novedad de mostrar los resultados para cada centro de votación, en lugar de hacerlo a nivel distrital como suele ser el caso. Para mi sorpresa, tuvo muchísima repercusión —asumí que solo iba a interesarle a unos pocos nerds de la política y la información pública. Combinando un mapa de radios censales de Bahía Blanca y la información extraída de REDATAM, se puede hacer —por ejemplo— un mapa del porcentaje de hogares con algún indicador de necesidades básicas insatisfechas:
Este ejemplo es lo mínimo que puede hacerse con esta información. La publicación en un formato más ameno que REDATAM, espero, facilitará su utilización y aumentará la conciencia sobre el valor de la información pública publicada de forma apropiada.
[Muchas gracias a Andy Tow y a Andrés Vázquez por la ayuda y comentarios]