Technology, and the spread of information it allows, can gather people together in squares in Egypt. What I find somewhat naive is the idea that you find within a lot of this web utopianism. Which is that, somehow, you can get a new democracy like this. Because underlying this, there’s the idea that all what democracy is, is all of us connected as nodal points of a network and —with feedback, a cybernetic idea— we’ll get to a shared harmony and out of that we’ll come to a shared harmony and order. Last time I looked, that’s not what democracy is, just a lot of individuals. That’s a naive market idea of democracy that we suffer from. Democracy is negotiating between the powerless and large, strong vested interests in society who often use their unequal access to power to their advantage at the expense of the less powerful. Democracy is about electing people who will stand up and represent you —the weak— and negotiate against the powerful. I’m very sympathetic to those movements, but self organizing systems are just that. They’re a retreat to managerialism, they’re a retreat to bureaucracy, they’re only a system. And that’s the ideology of our time: we’re all systems. What I argue, is that all those revolutions —if you look at them now— they all have gone backwards. They were incredibly noble, brave, hundreds of thousands people challenged those in power and got rid of them. What next? The idea that we’re all systems, and that system stabilizes itself is just that. We stabilize ourselves and that’s it. Is limiting or useless. (Cita tomada de una entrevista en el programa radial Little Atoms)
Los fines y comienzos de año traen muchas noticias sobre los presupuestos públicos. Los medios comienzan informando sobre los proyectos de presupuesto enviados a las legislaturas por los ejecutivos, luego reportan sobre el debate, y finalmente sobre las inevitables disconformidades de la oposición, sindicatos y privados. Esas coberturas suelen centrarse en las variaciones interanuales de las partidas; tal ministerio subió en un 10% su presupuesto de gastos, y así. Es una gran oportunidad, en general no aprovechada por los medios digitales argentinos, para usar herramientas de visualización de datos que permitan una mejor comprensión de esos cambios presupuestarios. Por el contrario, eligen escribir cosas como “el Ministerio X tendrá asignados 54.234 millones de pesos, lo que representa un incremento del 12.98% con respecto al año pasado“. Es decir, consideran a la web como una hoja de papel y se limitan a traducir a lenguaje escrito lo que podría ser mejor expresado gráfica e interactivamente. Quizás la razón sea que muchos gobiernos, salvo honrosas excepciones, insisten en disponibilizar información pública en formatos muy difíciles de procesar y poco apropiados para el intercambio de información. En este post vamos a tomar como ejemplo los presupuestos de gastos publicados por el gobierno de la provincia de Buenos Aires en formato PDF, el favorito de los funcionarios públicos.
(Primera página del presupuesto de gastos por jurisdicción y objeto (pcia BS.AS, 2013))
La imagen anterior es una captura de una página del presupuesto de gastos 2013 de la provincia de Buenos Aires. Queremos visualizar esa información. Si hubiera estado publicada en el formato apropiado, como CSV o inclusive Excel, podríamos habernos puesto manos a la obra. Pero está en PDF, así que vamos a tener que extraer los datos que contiene. Para eso vamos a usar Tabula, una herramienta opensource para liberartablasatrapadas en PDF que comencé a desarrollar el año pasado. Este video muestra cómo extraer una tabla como la del presupuesto con Tabula:
Vamos a obtener un archivo CSV, que tiene la siguiente estructura:
1.1.1.02.01.000 - PODER JUDICIAL - ADMINISTRACION DE JUSTICIA -,5623235000,5060399000,38500000,229600000,260736000,34000000, 0, 0, 0
ACE-0001 - SUPREMA CORTE DE JUSTICIA,1212978700,1132555800,12520300,56192800,11709800, 0, 0, 0 , 0
ACE-0002 - TASA RETRIBUTIVA DE SERVICIOS JUDICIALES (Ley 11.594),270000000,235300000, 0, 700000, 0,34000000, 0, 0 , 0
ACE-0003 - INFRAESTRUCTURA DE LA JUSTICIA DE PAZ LETRADA - LEY 10,4000000, 0, 100000,3400000, 500000, 0, 0, 0 , 0<
La primer línea representa el primer nivel de desagregación del presupuesto, seguido por el segundo nivel. Cada una de las filas contiene, además, las diferentes componentes del gasto (total, gastos en personal, etc). Para esta visualización, vamos a usar el total de cada partida. Para facilitar el procesamiento vamos a aplanar esta estructura mediante este script en lenguaje Python (pero podríamos haber usado Excel, OpenOffice Calc u OpenRefine):
Luego de procesar los datos originales con este programa, obtenemos otro CSV:
1.1.1.02.01.000,PODER JUDICIAL - ADMINISTRACION DE JUSTICIA -,1.1.1.02.01.000ACE-0001,SUPREMA CORTE DE JUSTICIA, 920826957, 767799850, 7711477, 135545330, 9770300, 0, 0, 0 , 0
1.1.1.02.01.000,PODER JUDICIAL - ADMINISTRACION DE JUSTICIA -,1.1.1.02.01.000ACE-0002,TASA RETRIBUTIVA DE SERVICIOS JUDICIALES (Ley 11.594), 146500000, 126750000, 0, 700000, 0, 19050000, 0, 0 , 0
1.1.1.02.01.000,PODER JUDICIAL - ADMINISTRACION DE JUSTICIA -,1.1.1.02.01.000ACE-0003,INFRAESTRUCTURA DE LA JUSTICIA DE PAZ LETRADA - LEY 10, 2500000, 0, 28000, 1972000, 500000, 0, 0, 0 , 0
1.1.1.02.01.000,PODER JUDICIAL - ADMINISTRACION DE JUSTICIA -,1.1.1.02.01.000ACE-0004,MATERIAL BIBLIOGRÁFICO E INFORMÁTICO PARA LAS BIBLIO, 4000000, 0, 1600000, 200000, 2200000, 0, 0, 0 , 0
Vemos que el script aplanó la estructura, incluyendo el primer nivel de desagregación en todas las filas del conjunto de datos resultante. Además, remueve los puntos separadores de miles y genera un identificador único para las partidas de segundo nivel. Con esto, ya estamos listos para subirlo a OpenSpending, el sistema de visualización de datos financieros gubernamentales construído por la Open Knowledge Foundation. No voy a explicar cómo usar OpenSpending; es bastante fácil una vez que se entiende el uso de su data modeler. Lo importante es que, con relativamente poco esfuerzo, podemos ir del PDF a una visualización:
El treemap, una buena manera de representar distribución de magnitudes en datos que tienen jerarquía, es solo una forma posible de representar la información. Según la necesidad, podíamos concentrarnos en la composición del gasto para algunas jurisdicciones, o mostrar variaciones interanuales.
Hay una enorme cantidad de información atrapada en archivos PDF. Hay dos razones para eso, como dije en la charla que dí en la MediaParty 2013 de Hacks/Hackers Buenos Aires. La primera es ignorancia; muchos no saben que el PDF un pésimo formato para compartir información. La segunda es pura maldad: extraer datos de archivos de PDF es por lo menos molesto y muchos se aprovechan de eso. Como becario 2013 del programa Knight-Mozilla OpenNews, trabajé bastante con conjuntos de datos en formato PDF. El resultado de ese interés fue Tabula, una herramienta libre para extraer tablas de archivos PDF que generó bastante entusiasmo en la comunidad de periodismo de datos y de datos abiertos. Sunlight Foundation organiza un hackatón de liberación de PDFs los días 17, 18 y 19 de Enero. Desde GarageLab vamos a sumarnos a esa iniciativa y convocamos a programadores, activistas e interesados en la liberación de datos para el día sábado 18 enero a partir de las 11:00 hs a reunirnos en nuestro espacio para trabajar en herramientas, técnicas y problemas de extracción de información desde archivos PDF. Si sos programador y tenés ganas de pasarte la tarde scrapeando PDFs, o si tenés algún conjunto de datos en PDF que quieras liberar, llená el formulario de inscripción (cupo limitado!) y acercate.
La Secretaría de Asuntos Municipales del Ministerio del Interior (Argentina) confecciona una base de datos bastante interesante: el listado de todos los municipios del país. Como mucha de la información generada por los estados —municipios, provincias o la nación—, no está publicada de manera tal que podamos usarla fácilmente. Esto está empezando a cambiar; algunos gobiernos están creando portales de información pública (datospublicos.gob.ar, data.buenosaires.gob.ar, gabierto.bahiablanca.gob.ar, entre otros) donde se ponen a disposición algunas de las bases de datos que genera el Estado (vemos que la información publicada en estos portales es bastante inocua —salvo honrosas excepciones—, pero también entendemos que esto recién comienza). Como proyecto de domingo, escribí un scraper para extraer el listado de municipios del sitio web en el que está publicado. El código está disponible bajo licencia MIT y los datos los subí a un Fusion Table.
Hay información interesante en esta base de datos: nombre del jefe de gobierno de cada municipio, ubicación geográfica, fecha de fundación, página web, información de contacto. Notablemente, sólo para el 30% de los más de 2200 municipios que figuran en esta base de datos hay un sitio web.
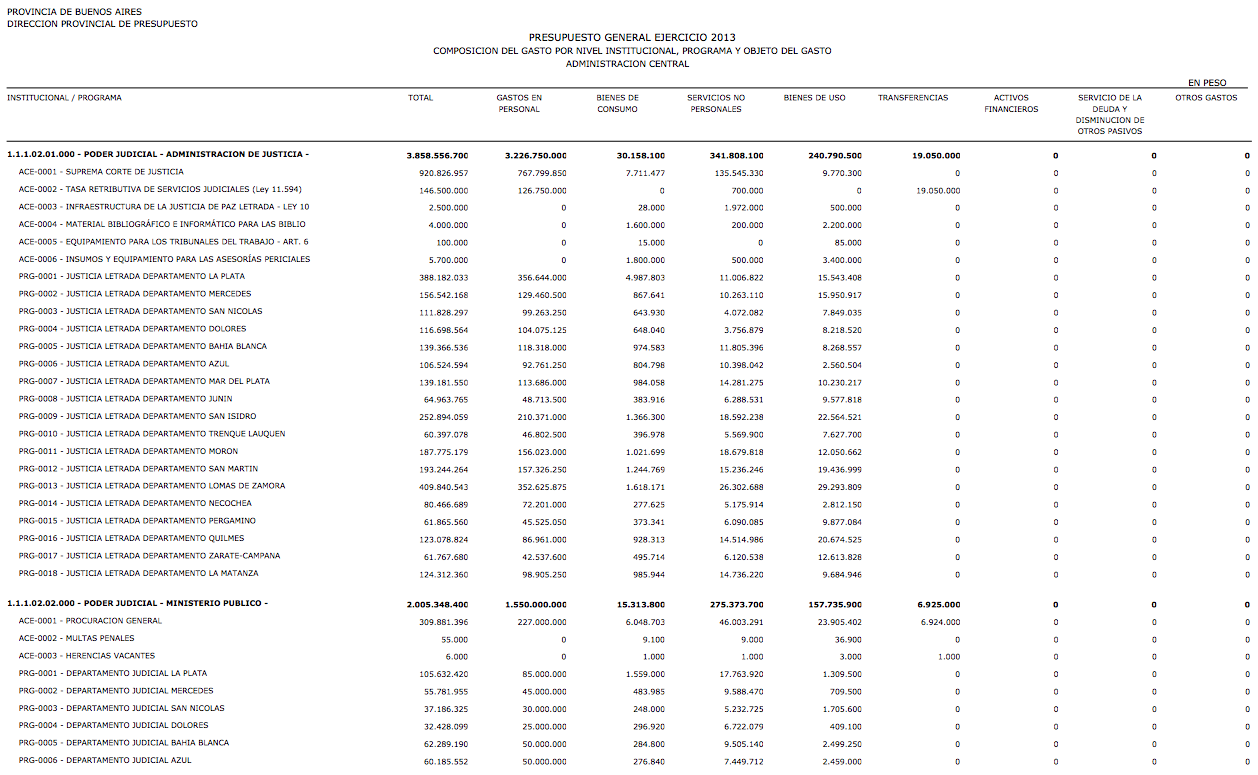 (Primera página del presupuesto de gastos por jurisdicción y objeto (pcia BS.AS, 2013))
(Primera página del presupuesto de gastos por jurisdicción y objeto (pcia BS.AS, 2013))