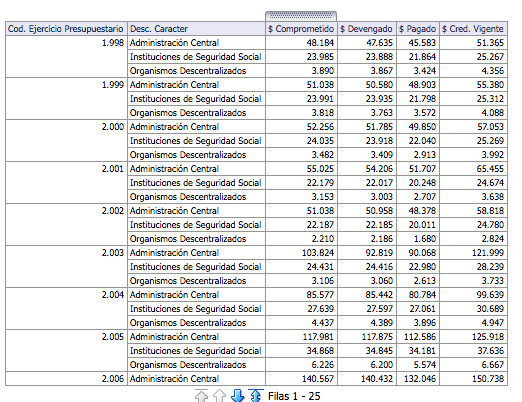
|
<saw:report xmlns:xsd="http://www.w3.org/2001/XMLSchema" |
|
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" |
|
xmlVersion="201201160" |
|
xmlns:saw="com.siebel.analytics.web/report/v1.1" |
|
xmlns:sawx="com.siebel.analytics.web/expression/v1.1"> |
|
<saw:criteria subjectArea=""SITIO DEL CIUDADANO"" |
|
xsi:type="saw:simpleCriteria" withinHierarchy="true"> |
|
<saw:columns> |
|
<saw:column columnID="c28" xsi:type="saw:regularColumn"> |
|
<saw:displayFormat> |
|
<saw:formatSpec visibility="hidden" suppress="default" |
|
interaction="default" /> |
|
</saw:displayFormat> |
|
<saw:tableHeading> |
|
<saw:caption fmt="html"> |
|
<saw:text>Institucion</saw:text> |
|
</saw:caption> |
|
</saw:tableHeading> |
|
<saw:columnHeading> |
|
<saw:displayFormat> |
|
<saw:formatSpec interaction="default" /> |
|
</saw:displayFormat> |
|
<saw:caption fmt="html"> |
|
<saw:text>Jurisdicción</saw:text> |
|
</saw:caption> |
|
</saw:columnHeading> |
|
<saw:columnFormula> |
|
<sawx:expr xsi:type="sawx:sqlExpression"> |
|
Institucion."Cod. Jurisdiccion"</sawx:expr> |
|
</saw:columnFormula> |
|
</saw:column> |
|
<saw:column columnID="c17" xsi:type="saw:regularColumn" |
|
forceGroupBy="true"> |
|
<saw:columnFormula> |
|
<sawx:expr xsi:type="sawx:sqlExpression"> |
|
Institucion."Cod. y Desc. Jurisdiccion"</sawx:expr> |
|
</saw:columnFormula> |
|
</saw:column> |
|
<saw:column columnID="c12" xsi:type="saw:regularColumn" |
|
forceGroupBy="true"> |
|
<saw:displayFormat> |
|
<saw:formatSpec suppress="default" |
|
interaction="default" /> |
|
</saw:displayFormat> |
|
<saw:columnHeading> |
|
<saw:displayFormat> |
|
<saw:formatSpec interaction="default" /> |
|
</saw:displayFormat> |
|
<saw:caption> |
|
<saw:text>Mes</saw:text> |
|
</saw:caption> |
|
</saw:columnHeading> |
|
<saw:tableHeading> |
|
<saw:caption> |
|
<saw:text>Tiempo</saw:text> |
|
</saw:caption> |
|
</saw:tableHeading> |
|
<saw:columnFormula> |
|
<sawx:expr xsi:type="sawx:sqlExpression">CAST(Tiempo.Mes |
|
as VARCHAR(2))</sawx:expr> |
|
</saw:columnFormula> |
|
<saw:dimensionSelection> |
|
<saw:selectionStep stepID="1" type="startWith" |
|
category="calcItem"> |
|
<saw:calcItem calcItemVers="1" function="Sum" |
|
uiFormula="'1'" id="calc_d24a025a05d90a4e"> |
|
<saw:caption> |
|
<saw:text>1</saw:text> |
|
</saw:caption> |
|
<saw:displayFormat /> |
|
<sawx:expr xsi:type="sawx:calcItemExpr"> |
|
<sawx:expr xsi:type="sawx:calcFunction" op="sum"> |
|
<sawx:expr xsi:type="saw:memberExpr"> |
|
<saw:staticMemberGroup> |
|
<saw:members xsi:type="saw:untypedMembers"> |
|
<saw:value>1</saw:value> |
|
</saw:members> |
|
</saw:staticMemberGroup> |
|
</sawx:expr> |
|
</sawx:expr> |
|
</sawx:expr> |
|
</saw:calcItem> |
|
</saw:selectionStep> |
|
<saw:selectionStep stepID="2" type="startWith" |
|
category="calcItem"> |
|
<saw:calcItem calcItemVers="1" function="Sum" |
|
uiFormula="'1','2'" id="calc_40fae10903894c2e"> |
|
<saw:caption> |
|
<saw:text>2</saw:text> |
|
</saw:caption> |
|
<sawx:expr xsi:type="sawx:calcItemExpr"> |
|
<sawx:expr xsi:type="sawx:calcFunction" op="sum"> |
|
<sawx:expr xsi:type="saw:memberExpr"> |
|
<saw:staticMemberGroup> |
|
<saw:members xsi:type="saw:untypedMembers"> |
|
<saw:value>1</saw:value> |
|
<saw:value>2</saw:value> |
|
</saw:members> |
|
</saw:staticMemberGroup> |
|
</sawx:expr> |
|
</sawx:expr> |
|
</sawx:expr> |
|
</saw:calcItem> |
|
</saw:selectionStep> |
|
<saw:selectionStep stepID="3" type="startWith" |
|
category="calcItem"> |
|
<saw:calcItem calcItemVers="1" function="Sum" |
|
uiFormula="'1','2','3'" id="calc_fbc5eb33b084d79f"> |
|
<saw:caption> |
|
<saw:text>3</saw:text> |
|
</saw:caption> |
|
<sawx:expr xsi:type="sawx:calcItemExpr"> |
|
<sawx:expr xsi:type="sawx:calcFunction" op="sum"> |
|
<sawx:expr xsi:type="saw:memberExpr"> |
|
<saw:staticMemberGroup> |
|
<saw:members xsi:type="saw:untypedMembers"> |
|
<saw:value>1</saw:value> |
|
<saw:value>2</saw:value> |
|
<saw:value>3</saw:value> |
|
</saw:members> |
|
</saw:staticMemberGroup> |
|
</sawx:expr> |
|
</sawx:expr> |
|
</sawx:expr> |
|
</saw:calcItem> |
|
</saw:selectionStep> |
|
<saw:selectionStep stepID="4" type="startWith" |
|
category="calcItem"> |
|
<saw:calcItem calcItemVers="1" function="Sum" |
|
uiFormula="'1','2','3','4'" id="calc_d1b07c656ea93e16"> |
|
<saw:caption> |
|
<saw:text>4</saw:text> |
|
</saw:caption> |
|
<sawx:expr xsi:type="sawx:calcItemExpr"> |
|
<sawx:expr xsi:type="sawx:calcFunction" op="sum"> |
|
<sawx:expr xsi:type="saw:memberExpr"> |
|
<saw:staticMemberGroup> |
|
<saw:members xsi:type="saw:untypedMembers"> |
|
<saw:value>1</saw:value> |
|
<saw:value>2</saw:value> |
|
<saw:value>3</saw:value> |
|
<saw:value>4</saw:value> |
|
</saw:members> |
|
</saw:staticMemberGroup> |
|
</sawx:expr> |
|
</sawx:expr> |
|
</sawx:expr> |
|
</saw:calcItem> |
|
</saw:selectionStep> |
|
<saw:selectionStep stepID="5" type="startWith" |
|
category="calcItem"> |
|
<saw:calcItem calcItemVers="1" function="Sum" |
|
uiFormula="'1','2','3','4','5'" |
|
id="calc_0d7000d13f881315"> |
|
<saw:caption> |
|
<saw:text>5</saw:text> |
|
</saw:caption> |
|
<sawx:expr xsi:type="sawx:calcItemExpr"> |
|
<sawx:expr xsi:type="sawx:calcFunction" op="sum"> |
|
<sawx:expr xsi:type="saw:memberExpr"> |
|
<saw:staticMemberGroup> |
|
<saw:members xsi:type="saw:untypedMembers"> |
|
<saw:value>1</saw:value> |
|
<saw:value>2</saw:value> |
|
<saw:value>3</saw:value> |
|
<saw:value>4</saw:value> |
|
<saw:value>5</saw:value> |
|
</saw:members> |
|
</saw:staticMemberGroup> |
|
</sawx:expr> |
|
</sawx:expr> |
|
</sawx:expr> |
|
</saw:calcItem> |
|
</saw:selectionStep> |
|
<saw:selectionStep stepID="6" type="startWith" |
|
category="calcItem"> |
|
<saw:calcItem calcItemVers="1" function="Sum" |
|
uiFormula="'1','2','3','4','5','6'" |
|
id="calc_dcd64b5456bee7b2"> |
|
<saw:caption> |
|
<saw:text>6</saw:text> |
|
</saw:caption> |
|
<sawx:expr xsi:type="sawx:calcItemExpr"> |
|
<sawx:expr xsi:type="sawx:calcFunction" op="sum"> |
|
<sawx:expr xsi:type="saw:memberExpr"> |
|
<saw:staticMemberGroup> |
|
<saw:members xsi:type="saw:untypedMembers"> |
|
<saw:value>1</saw:value> |
|
<saw:value>2</saw:value> |
|
<saw:value>3</saw:value> |
|
<saw:value>4</saw:value> |
|
<saw:value>5</saw:value> |
|
<saw:value>6</saw:value> |
|
</saw:members> |
|
</saw:staticMemberGroup> |
|
</sawx:expr> |
|
</sawx:expr> |
|
</sawx:expr> |
|
</saw:calcItem> |
|
</saw:selectionStep> |
|
<saw:selectionStep stepID="7" type="startWith" |
|
category="calcItem"> |
|
<saw:calcItem calcItemVers="1" function="Sum" |
|
uiFormula="'1','2','3','4','5','6','7'" |
|
id="calc_534c68ff2f14c564"> |
|
<saw:caption> |
|
<saw:text>7</saw:text> |
|
</saw:caption> |
|
<sawx:expr xsi:type="sawx:calcItemExpr"> |
|
<sawx:expr xsi:type="sawx:calcFunction" op="sum"> |
|
<sawx:expr xsi:type="saw:memberExpr"> |
|
<saw:staticMemberGroup> |
|
<saw:members xsi:type="saw:untypedMembers"> |
|
<saw:value>1</saw:value> |
|
<saw:value>2</saw:value> |
|
<saw:value>3</saw:value> |
|
<saw:value>4</saw:value> |
|
<saw:value>5</saw:value> |
|
<saw:value>6</saw:value> |
|
<saw:value>7</saw:value> |
|
</saw:members> |
|
</saw:staticMemberGroup> |
|
</sawx:expr> |
|
</sawx:expr> |
|
</sawx:expr> |
|
</saw:calcItem> |
|
</saw:selectionStep> |
|
<saw:selectionStep stepID="8" type="startWith" |
|
category="calcItem"> |
|
<saw:calcItem calcItemVers="1" function="Sum" |
|
uiFormula="'1','2','3','4','5','6','7','8'" |
|
id="calc_266613bf61f9343d"> |
|
<saw:caption> |
|
<saw:text>8</saw:text> |
|
</saw:caption> |
|
<sawx:expr xsi:type="sawx:calcItemExpr"> |
|
<sawx:expr xsi:type="sawx:calcFunction" op="sum"> |
|
<sawx:expr xsi:type="saw:memberExpr"> |
|
<saw:staticMemberGroup> |
|
<saw:members xsi:type="saw:untypedMembers"> |
|
<saw:value>1</saw:value> |
|
<saw:value>2</saw:value> |
|
<saw:value>3</saw:value> |
|
<saw:value>4</saw:value> |
|
<saw:value>5</saw:value> |
|
<saw:value>6</saw:value> |
|
<saw:value>7</saw:value> |
|
<saw:value>8</saw:value> |
|
</saw:members> |
|
</saw:staticMemberGroup> |
|
</sawx:expr> |
|
</sawx:expr> |
|
</sawx:expr> |
|
</saw:calcItem> |
|
</saw:selectionStep> |
|
<saw:selectionStep stepID="9" type="startWith" |
|
category="calcItem"> |
|
<saw:calcItem calcItemVers="1" function="Sum" |
|
uiFormula="'1','2','3','4','5','6','7','8','9'" |
|
id="calc_0fa6097f29f6dd87"> |
|
<saw:caption> |
|
<saw:text>9</saw:text> |
|
</saw:caption> |
|
<sawx:expr xsi:type="sawx:calcItemExpr"> |
|
<sawx:expr xsi:type="sawx:calcFunction" op="sum"> |
|
<sawx:expr xsi:type="saw:memberExpr"> |
|
<saw:staticMemberGroup> |
|
<saw:members xsi:type="saw:untypedMembers"> |
|
<saw:value>1</saw:value> |
|
<saw:value>2</saw:value> |
|
<saw:value>3</saw:value> |
|
<saw:value>4</saw:value> |
|
<saw:value>5</saw:value> |
|
<saw:value>6</saw:value> |
|
<saw:value>7</saw:value> |
|
<saw:value>8</saw:value> |
|
<saw:value>9</saw:value> |
|
</saw:members> |
|
</saw:staticMemberGroup> |
|
</sawx:expr> |
|
</sawx:expr> |
|
</sawx:expr> |
|
</saw:calcItem> |
|
</saw:selectionStep> |
|
<saw:selectionStep stepID="10" type="startWith" |
|
category="calcItem"> |
|
<saw:calcItem calcItemVers="1" function="Sum" |
|
uiFormula="'1','2','3','4','5','6','7','8','9','10'" |
|
id="calc_cf65bdcbd82662d1"> |
|
<saw:caption> |
|
<saw:text>10</saw:text> |
|
</saw:caption> |
|
<sawx:expr xsi:type="sawx:calcItemExpr"> |
|
<sawx:expr xsi:type="sawx:calcFunction" op="sum"> |
|
<sawx:expr xsi:type="saw:memberExpr"> |
|
<saw:staticMemberGroup> |
|
<saw:members xsi:type="saw:untypedMembers"> |
|
<saw:value>1</saw:value> |
|
<saw:value>2</saw:value> |
|
<saw:value>3</saw:value> |
|
<saw:value>4</saw:value> |
|
<saw:value>5</saw:value> |
|
<saw:value>6</saw:value> |
|
<saw:value>7</saw:value> |
|
<saw:value>8</saw:value> |
|
<saw:value>9</saw:value> |
|
<saw:value>10</saw:value> |
|
</saw:members> |
|
</saw:staticMemberGroup> |
|
</sawx:expr> |
|
</sawx:expr> |
|
</sawx:expr> |
|
</saw:calcItem> |
|
</saw:selectionStep> |
|
<saw:selectionStep stepID="11" type="startWith" |
|
category="calcItem"> |
|
<saw:calcItem calcItemVers="1" function="Sum" |
|
uiFormula="'1','2','3','4','5','6','7','8','9','10','11'" |
|
id="calc_ad0a80b0965203ea"> |
|
<saw:caption> |
|
<saw:text>11</saw:text> |
|
</saw:caption> |
|
<sawx:expr xsi:type="sawx:calcItemExpr"> |
|
<sawx:expr xsi:type="sawx:calcFunction" op="sum"> |
|
<sawx:expr xsi:type="saw:memberExpr"> |
|
<saw:staticMemberGroup> |
|
<saw:members xsi:type="saw:untypedMembers"> |
|
<saw:value>1</saw:value> |
|
<saw:value>2</saw:value> |
|
<saw:value>3</saw:value> |
|
<saw:value>4</saw:value> |
|
<saw:value>5</saw:value> |
|
<saw:value>6</saw:value> |
|
<saw:value>7</saw:value> |
|
<saw:value>8</saw:value> |
|
<saw:value>9</saw:value> |
|
<saw:value>10</saw:value> |
|
<saw:value>11</saw:value> |
|
</saw:members> |
|
</saw:staticMemberGroup> |
|
</sawx:expr> |
|
</sawx:expr> |
|
</sawx:expr> |
|
</saw:calcItem> |
|
</saw:selectionStep> |
|
</saw:dimensionSelection> |
|
</saw:column> |
|
<saw:column columnID="c7" xsi:type="saw:regularColumn" |
|
forceGroupBy="true"> |
|
<saw:displayFormat> |
|
<saw:formatSpec interaction="action" fontSize="9" |
|
wrapText="true" suppress="repeat"> |
|
<saw:dataFormat xsi:type="saw:currency" commas="true" |
|
negativeType="minus" minDigits="2" maxDigits="2" |
|
currencyTag="int:$" /> |
|
<saw:actionLinks showPopupMenuForOneLink="true"> |
|
<saw:actionLink xsi:type="saw:actionLink" |
|
actionLinkID="19755124d644773b"> |
|
<saw:action> |
|
<saw:actionName>Navigate To BI |
|
Content</saw:actionName> |
|
<saw:parameters allowExtraParameters="true"> |
|
<saw:parameter name="__navigateToBIContent__" |
|
type="string" mandatory="true" removable="true" |
|
order="999" multiValues="false"> |
|
<saw:prompt> |
|
__navigateToBIContent__</saw:prompt> |
|
</saw:parameter> |
|
</saw:parameters> |
|
<saw:assignments> |
|
<saw:assign xsi:type="saw:stringAssign" |
|
name="__navigateToBIContent__" fixed="true" |
|
hidden="true" parentFixed="true" |
|
parentHidden="true"> |
|
<saw:value> |
|
/shared/SiCi/Ejecucion_por_Servicio</saw:value> |
|
</saw:assign> |
|
</saw:assignments> |
|
<saw:implementation xsi:type="saw:ScriptActionType" |
|
executeOnClient="true"> |
|
<saw:functionName> |
|
__navigateToBIContent__</saw:functionName> |
|
<saw:scriptLanguage> |
|
JScript</saw:scriptLanguage> |
|
<saw:scriptPath /> |
|
</saw:implementation> |
|
<saw:clientImplementation> |
|
<saw:customisation invokeConfirmation="false" /> |
|
</saw:clientImplementation> |
|
</saw:action> |
|
<saw:caption> |
|
<saw:text>Gastos por Servicio / |
|
Entidad</saw:text> |
|
</saw:caption> |
|
</saw:actionLink> |
|
<saw:actionLink xsi:type="saw:actionLink" |
|
actionLinkID="940140d7ed77b8a7"> |
|
<saw:action> |
|
<saw:actionName>Navigate To BI |
|
Content</saw:actionName> |
|
<saw:parameters allowExtraParameters="true"> |
|
<saw:parameter name="__navigateToBIContent__" |
|
type="string" mandatory="true" removable="true" |
|
order="999" multiValues="false"> |
|
<saw:prompt> |
|
__navigateToBIContent__</saw:prompt> |
|
</saw:parameter> |
|
</saw:parameters> |
|
<saw:assignments> |
|
<saw:assign xsi:type="saw:stringAssign" |
|
name="__navigateToBIContent__" fixed="true" |
|
hidden="true" parentFixed="true" |
|
parentHidden="true"> |
|
<saw:value> |
|
/shared/SiCi/Ejecucion_por_Programa</saw:value> |
|
</saw:assign> |
|
</saw:assignments> |
|
<saw:implementation xsi:type="saw:ScriptActionType" |
|
executeOnClient="true"> |
|
<saw:functionName> |
|
__navigateToBIContent__</saw:functionName> |
|
<saw:scriptLanguage> |
|
JScript</saw:scriptLanguage> |
|
<saw:scriptPath /> |
|
</saw:implementation> |
|
<saw:clientImplementation> |
|
<saw:customisation invokeConfirmation="false" /> |
|
</saw:clientImplementation> |
|
</saw:action> |
|
<saw:caption> |
|
<saw:text>Gastos por Programas</saw:text> |
|
</saw:caption> |
|
</saw:actionLink> |
|
<saw:actionLink xsi:type="saw:actionLink" |
|
actionLinkID="e6817c079a682f30"> |
|
<saw:action> |
|
<saw:actionName>Navigate To BI |
|
Content</saw:actionName> |
|
<saw:parameters allowExtraParameters="true"> |
|
<saw:parameter name="__navigateToBIContent__" |
|
type="string" mandatory="true" removable="true" |
|
order="999" multiValues="false"> |
|
<saw:prompt> |
|
__navigateToBIContent__</saw:prompt> |
|
</saw:parameter> |
|
</saw:parameters> |
|
<saw:assignments> |
|
<saw:assign xsi:type="saw:stringAssign" |
|
name="__navigateToBIContent__" fixed="true" |
|
hidden="true" parentFixed="true" |
|
parentHidden="true"> |
|
<saw:value> |
|
/shared/SiCi/Ejecucion_por_Objeto_Gasto</saw:value> |
|
</saw:assign> |
|
</saw:assignments> |
|
<saw:implementation xsi:type="saw:ScriptActionType" |
|
executeOnClient="true"> |
|
<saw:functionName> |
|
__navigateToBIContent__</saw:functionName> |
|
<saw:scriptLanguage> |
|
JScript</saw:scriptLanguage> |
|
<saw:scriptPath /> |
|
</saw:implementation> |
|
<saw:clientImplementation> |
|
<saw:customisation invokeConfirmation="false" /> |
|
</saw:clientImplementation> |
|
</saw:action> |
|
<saw:caption> |
|
<saw:text>Gastos por Objeto del Gasto</saw:text> |
|
</saw:caption> |
|
</saw:actionLink> |
|
<saw:actionLink xsi:type="saw:actionLink" |
|
actionLinkID="40a0002543a4bcfc"> |
|
<saw:action> |
|
<saw:actionName>Navigate To BI |
|
Content</saw:actionName> |
|
<saw:parameters allowExtraParameters="true"> |
|
<saw:parameter name="__navigateToBIContent__" |
|
type="string" mandatory="true" removable="true" |
|
order="999" multiValues="false"> |
|
<saw:prompt> |
|
__navigateToBIContent__</saw:prompt> |
|
</saw:parameter> |
|
</saw:parameters> |
|
<saw:assignments> |
|
<saw:assign xsi:type="saw:stringAssign" |
|
name="__navigateToBIContent__" fixed="true" |
|
hidden="true" parentFixed="true" |
|
parentHidden="true"> |
|
<saw:value> |
|
/shared/SiCi/Ejecucion_por_Fuente_Financiamiento</saw:value> |
|
</saw:assign> |
|
</saw:assignments> |
|
<saw:implementation xsi:type="saw:ScriptActionType" |
|
executeOnClient="true"> |
|
<saw:functionName> |
|
__navigateToBIContent__</saw:functionName> |
|
<saw:scriptLanguage> |
|
JScript</saw:scriptLanguage> |
|
<saw:scriptPath /> |
|
</saw:implementation> |
|
<saw:clientImplementation> |
|
<saw:customisation invokeConfirmation="false" /> |
|
</saw:clientImplementation> |
|
</saw:action> |
|
<saw:caption> |
|
<saw:text>Gastos por Fuente de |
|
Financiamiento</saw:text> |
|
</saw:caption> |
|
</saw:actionLink> |
|
<saw:actionLink xsi:type="saw:actionLink" |
|
actionLinkID="8079bae69761d202"> |
|
<saw:action> |
|
<saw:actionName>Navigate To BI |
|
Content</saw:actionName> |
|
<saw:parameters allowExtraParameters="true"> |
|
<saw:parameter name="__navigateToBIContent__" |
|
type="string" mandatory="true" removable="true" |
|
order="999" multiValues="false"> |
|
<saw:prompt> |
|
__navigateToBIContent__</saw:prompt> |
|
</saw:parameter> |
|
</saw:parameters> |
|
<saw:assignments> |
|
<saw:assign xsi:type="saw:stringAssign" |
|
name="__navigateToBIContent__" fixed="true" |
|
hidden="true" parentFixed="true" |
|
parentHidden="true"> |
|
<saw:value> |
|
/shared/SiCi/Ejecucion_por_Finalidad_Funcion</saw:value> |
|
</saw:assign> |
|
</saw:assignments> |
|
<saw:implementation xsi:type="saw:ScriptActionType" |
|
executeOnClient="true"> |
|
<saw:functionName> |
|
__navigateToBIContent__</saw:functionName> |
|
<saw:scriptLanguage> |
|
JScript</saw:scriptLanguage> |
|
<saw:scriptPath /> |
|
</saw:implementation> |
|
<saw:clientImplementation> |
|
<saw:customisation invokeConfirmation="false" /> |
|
</saw:clientImplementation> |
|
</saw:action> |
|
<saw:caption> |
|
<saw:text>Gastos por Finalidad |
|
Función</saw:text> |
|
</saw:caption> |
|
</saw:actionLink> |
|
<saw:actionLink xsi:type="saw:actionLink" |
|
actionLinkID="a3bf040f0a98c0f9"> |
|
<saw:action> |
|
<saw:actionName>Navigate To BI |
|
Content</saw:actionName> |
|
<saw:parameters allowExtraParameters="true"> |
|
<saw:parameter name="__navigateToBIContent__" |
|
type="string" mandatory="true" removable="true" |
|
order="999" multiValues="false"> |
|
<saw:prompt> |
|
__navigateToBIContent__</saw:prompt> |
|
</saw:parameter> |
|
</saw:parameters> |
|
<saw:assignments> |
|
<saw:assign xsi:type="saw:stringAssign" |
|
name="__navigateToBIContent__" fixed="true" |
|
hidden="true" parentFixed="true" |
|
parentHidden="true"> |
|
<saw:value> |
|
/shared/SiCi/Ejecucion_por_Caracter</saw:value> |
|
</saw:assign> |
|
</saw:assignments> |
|
<saw:implementation xsi:type="saw:ScriptActionType" |
|
executeOnClient="true"> |
|
<saw:functionName> |
|
__navigateToBIContent__</saw:functionName> |
|
<saw:scriptLanguage> |
|
JScript</saw:scriptLanguage> |
|
<saw:scriptPath /> |
|
</saw:implementation> |
|
<saw:clientImplementation> |
|
<saw:customisation invokeConfirmation="false" /> |
|
</saw:clientImplementation> |
|
</saw:action> |
|
<saw:caption> |
|
<saw:text>Gastos por |
|
Carácter</saw:text> |
|
</saw:caption> |
|
</saw:actionLink> |
|
</saw:actionLinks> |
|
</saw:formatSpec> |
|
</saw:displayFormat> |
|
<saw:columnHeading> |
|
<saw:displayFormat> |
|
<saw:formatSpec /> |
|
</saw:displayFormat> |
|
<saw:caption fmt="html"> |
|
<saw:text>Presupuestado</saw:text> |
|
</saw:caption> |
|
</saw:columnHeading> |
|
<saw:tableHeading> |
|
<saw:caption fmt="html"> |
|
<saw:text>Indicadores Credito</saw:text> |
|
</saw:caption> |
|
</saw:tableHeading> |
|
<saw:columnFormula> |
|
<sawx:expr xsi:type="sawx:sqlExpression">"Indicadores |
|
Credito"."$ Cred. Vigente"</sawx:expr> |
|
</saw:columnFormula> |
|
</saw:column> |
|
<saw:column columnID="c8" xsi:type="saw:regularColumn" |
|
forceGroupBy="true"> |
|
<saw:displayFormat> |
|
<saw:formatSpec suppress="default" interaction="action"> |
|
<saw:dataFormat xsi:type="saw:currency" |
|
currencyTag="loc:es-AR" commas="true" |
|
negativeType="minus" minDigits="2" maxDigits="2" /> |
|
<saw:actionLinks> |
|
<saw:actionLink xsi:type="saw:actionLink" |
|
actionLinkID="390d9488f9b35ecd"> |
|
<saw:action> |
|
<saw:actionName>Navigate To BI |
|
Content</saw:actionName> |
|
<saw:parameters allowExtraParameters="true"> |
|
<saw:parameter name="__navigateToBIContent__" |
|
type="string" mandatory="true" removable="true" |
|
order="999" multiValues="false"> |
|
<saw:prompt> |
|
__navigateToBIContent__</saw:prompt> |
|
</saw:parameter> |
|
</saw:parameters> |
|
<saw:assignments> |
|
<saw:assign xsi:type="saw:stringAssign" |
|
name="__navigateToBIContent__" fixed="true" |
|
hidden="true" parentFixed="true" |
|
parentHidden="true"> |
|
<saw:value> |
|
/shared/SiCi/Ejecucion_por_Servicio</saw:value> |
|
</saw:assign> |
|
</saw:assignments> |
|
<saw:implementation xsi:type="saw:ScriptActionType" |
|
executeOnClient="true"> |
|
<saw:functionName> |
|
__navigateToBIContent__</saw:functionName> |
|
<saw:scriptLanguage> |
|
JScript</saw:scriptLanguage> |
|
<saw:scriptPath /> |
|
</saw:implementation> |
|
<saw:clientImplementation> |
|
<saw:customisation invokeConfirmation="false" /> |
|
</saw:clientImplementation> |
|
</saw:action> |
|
<saw:caption> |
|
<saw:text>Gastos por Servicio / |
|
Entidad</saw:text> |
|
</saw:caption> |
|
</saw:actionLink> |
|
<saw:actionLink xsi:type="saw:actionLink" |
|
actionLinkID="49b9511a49e74f7a"> |
|
<saw:action> |
|
<saw:actionName>Navigate To BI |
|
Content</saw:actionName> |
|
<saw:parameters allowExtraParameters="true"> |
|
<saw:parameter name="__navigateToBIContent__" |
|
type="string" mandatory="true" removable="true" |
|
order="999" multiValues="false"> |
|
<saw:prompt> |
|
__navigateToBIContent__</saw:prompt> |
|
</saw:parameter> |
|
</saw:parameters> |
|
<saw:assignments> |
|
<saw:assign xsi:type="saw:stringAssign" |
|
name="__navigateToBIContent__" fixed="true" |
|
hidden="true" parentFixed="true" |
|
parentHidden="true"> |
|
<saw:value> |
|
/shared/SiCi/Ejecucion_por_Programa</saw:value> |
|
</saw:assign> |
|
</saw:assignments> |
|
<saw:implementation xsi:type="saw:ScriptActionType" |
|
executeOnClient="true"> |
|
<saw:functionName> |
|
__navigateToBIContent__</saw:functionName> |
|
<saw:scriptLanguage> |
|
JScript</saw:scriptLanguage> |
|
<saw:scriptPath /> |
|
</saw:implementation> |
|
<saw:clientImplementation> |
|
<saw:customisation invokeConfirmation="false" /> |
|
</saw:clientImplementation> |
|
</saw:action> |
|
<saw:caption> |
|
<saw:text>Gastos por Programas</saw:text> |
|
</saw:caption> |
|
</saw:actionLink> |
|
<saw:actionLink xsi:type="saw:actionLink" |
|
actionLinkID="b37376268ba5030e"> |
|
<saw:action> |
|
<saw:actionName>Navigate To BI |
|
Content</saw:actionName> |
|
<saw:parameters allowExtraParameters="true"> |
|
<saw:parameter name="__navigateToBIContent__" |
|
type="string" mandatory="true" removable="true" |
|
order="999" multiValues="false"> |
|
<saw:prompt> |
|
__navigateToBIContent__</saw:prompt> |
|
</saw:parameter> |
|
</saw:parameters> |
|
<saw:assignments> |
|
<saw:assign xsi:type="saw:stringAssign" |
|
name="__navigateToBIContent__" fixed="true" |
|
hidden="true" parentFixed="true" |
|
parentHidden="true"> |
|
<saw:value> |
|
/shared/SiCi/Ejecucion_por_Objeto_Gasto</saw:value> |
|
</saw:assign> |
|
</saw:assignments> |
|
<saw:implementation xsi:type="saw:ScriptActionType" |
|
executeOnClient="true"> |
|
<saw:functionName> |
|
__navigateToBIContent__</saw:functionName> |
|
<saw:scriptLanguage> |
|
JScript</saw:scriptLanguage> |
|
<saw:scriptPath /> |
|
</saw:implementation> |
|
<saw:clientImplementation> |
|
<saw:customisation invokeConfirmation="false" /> |
|
</saw:clientImplementation> |
|
</saw:action> |
|
<saw:caption> |
|
<saw:text>Gastos por Objeto del Gasto</saw:text> |
|
</saw:caption> |
|
</saw:actionLink> |
|
<saw:actionLink xsi:type="saw:actionLink" |
|
actionLinkID="fb8a442e4e2ccc31"> |
|
<saw:action> |
|
<saw:actionName>Navigate To BI |
|
Content</saw:actionName> |
|
<saw:parameters allowExtraParameters="true"> |
|
<saw:parameter name="__navigateToBIContent__" |
|
type="string" mandatory="true" removable="true" |
|
order="999" multiValues="false"> |
|
<saw:prompt> |
|
__navigateToBIContent__</saw:prompt> |
|
</saw:parameter> |
|
</saw:parameters> |
|
<saw:assignments> |
|
<saw:assign xsi:type="saw:stringAssign" |
|
name="__navigateToBIContent__" fixed="true" |
|
hidden="true" parentFixed="true" |
|
parentHidden="true"> |
|
<saw:value> |
|
/shared/SiCi/Ejecucion_por_Fuente_Financiamiento</saw:value> |
|
</saw:assign> |
|
</saw:assignments> |
|
<saw:implementation xsi:type="saw:ScriptActionType" |
|
executeOnClient="true"> |
|
<saw:functionName> |
|
__navigateToBIContent__</saw:functionName> |
|
<saw:scriptLanguage> |
|
JScript</saw:scriptLanguage> |
|
<saw:scriptPath /> |
|
</saw:implementation> |
|
<saw:clientImplementation> |
|
<saw:customisation invokeConfirmation="false" /> |
|
</saw:clientImplementation> |
|
</saw:action> |
|
<saw:caption> |
|
<saw:text>Gastos por Fuente de |
|
Financiamiento</saw:text> |
|
</saw:caption> |
|
</saw:actionLink> |
|
<saw:actionLink xsi:type="saw:actionLink" |
|
actionLinkID="e98c062689af7be8"> |
|
<saw:action> |
|
<saw:actionName>Navigate To BI |
|
Content</saw:actionName> |
|
<saw:parameters allowExtraParameters="true"> |
|
<saw:parameter name="__navigateToBIContent__" |
|
type="string" mandatory="true" removable="true" |
|
order="999" multiValues="false"> |
|
<saw:prompt> |
|
__navigateToBIContent__</saw:prompt> |
|
</saw:parameter> |
|
</saw:parameters> |
|
<saw:assignments> |
|
<saw:assign xsi:type="saw:stringAssign" |
|
name="__navigateToBIContent__" fixed="true" |
|
hidden="true" parentFixed="true" |
|
parentHidden="true"> |
|
<saw:value> |
|
/shared/SiCi/Ejecucion_por_Finalidad_Funcion</saw:value> |
|
</saw:assign> |
|
</saw:assignments> |
|
<saw:implementation xsi:type="saw:ScriptActionType" |
|
executeOnClient="true"> |
|
<saw:functionName> |
|
__navigateToBIContent__</saw:functionName> |
|
<saw:scriptLanguage> |
|
JScript</saw:scriptLanguage> |
|
<saw:scriptPath /> |
|
</saw:implementation> |
|
<saw:clientImplementation> |
|
<saw:customisation invokeConfirmation="false" /> |
|
</saw:clientImplementation> |
|
</saw:action> |
|
<saw:caption> |
|
<saw:text>Gastos por Finalidad |
|
Función</saw:text> |
|
</saw:caption> |
|
</saw:actionLink> |
|
<saw:actionLink xsi:type="saw:actionLink" |
|
actionLinkID="9787b50d35eff442"> |
|
<saw:action> |
|
<saw:actionName>Navigate To BI |
|
Content</saw:actionName> |
|
<saw:parameters allowExtraParameters="true"> |
|
<saw:parameter name="__navigateToBIContent__" |
|
type="string" mandatory="true" removable="true" |
|
order="999" multiValues="false"> |
|
<saw:prompt> |
|
__navigateToBIContent__</saw:prompt> |
|
</saw:parameter> |
|
</saw:parameters> |
|
<saw:assignments> |
|
<saw:assign xsi:type="saw:stringAssign" |
|
name="__navigateToBIContent__" fixed="true" |
|
hidden="true" parentFixed="true" |
|
parentHidden="true"> |
|
<saw:value> |
|
/shared/SiCi/Ejecucion_por_Caracter</saw:value> |
|
</saw:assign> |
|
</saw:assignments> |
|
<saw:implementation xsi:type="saw:ScriptActionType" |
|
executeOnClient="true"> |
|
<saw:functionName> |
|
__navigateToBIContent__</saw:functionName> |
|
<saw:scriptLanguage> |
|
JScript</saw:scriptLanguage> |
|
<saw:scriptPath /> |
|
</saw:implementation> |
|
<saw:clientImplementation> |
|
<saw:customisation invokeConfirmation="false" /> |
|
</saw:clientImplementation> |
|
</saw:action> |
|
<saw:caption> |
|
<saw:text>Gastos por |
|
Carácter</saw:text> |
|
</saw:caption> |
|
</saw:actionLink> |
|
</saw:actionLinks> |
|
</saw:formatSpec> |
|
</saw:displayFormat> |
|
<saw:columnHeading> |
|
<saw:displayFormat> |
|
<saw:formatSpec interaction="default" /> |
|
</saw:displayFormat> |
|
<saw:caption> |
|
<saw:text>Comprometido</saw:text> |
|
</saw:caption> |
|
</saw:columnHeading> |
|
<saw:tableHeading> |
|
<saw:caption> |
|
<saw:text>Indicadores Credito</saw:text> |
|
</saw:caption> |
|
</saw:tableHeading> |
|
<saw:columnFormula> |
|
<sawx:expr xsi:type="sawx:sqlExpression">"Indicadores |
|
Credito"."$ Comprometido"</sawx:expr> |
|
</saw:columnFormula> |
|
</saw:column> |
|
<saw:column columnID="c9" xsi:type="saw:regularColumn" |
|
forceGroupBy="true"> |
|
<saw:displayFormat> |
|
<saw:formatSpec suppress="default" interaction="action"> |
|
<saw:dataFormat xsi:type="saw:currency" |
|
currencyTag="loc:es-AR" commas="true" |
|
negativeType="minus" minDigits="2" maxDigits="2" /> |
|
<saw:actionLinks> |
|
<saw:actionLink xsi:type="saw:actionLink" |
|
actionLinkID="a956dec3edf6273e"> |
|
<saw:action> |
|
<saw:actionName>Navigate To BI |
|
Content</saw:actionName> |
|
<saw:parameters allowExtraParameters="true"> |
|
<saw:parameter name="__navigateToBIContent__" |
|
type="string" mandatory="true" removable="true" |
|
order="999" multiValues="false"> |
|
<saw:prompt> |
|
__navigateToBIContent__</saw:prompt> |
|
</saw:parameter> |
|
</saw:parameters> |
|
<saw:assignments> |
|
<saw:assign xsi:type="saw:stringAssign" |
|
name="__navigateToBIContent__" fixed="true" |
|
hidden="true" parentFixed="true" |
|
parentHidden="true"> |
|
<saw:value> |
|
/shared/SiCi/Ejecucion_por_Servicio</saw:value> |
|
</saw:assign> |
|
</saw:assignments> |
|
<saw:implementation xsi:type="saw:ScriptActionType" |
|
executeOnClient="true"> |
|
<saw:functionName> |
|
__navigateToBIContent__</saw:functionName> |
|
<saw:scriptLanguage> |
|
JScript</saw:scriptLanguage> |
|
<saw:scriptPath /> |
|
</saw:implementation> |
|
<saw:clientImplementation> |
|
<saw:customisation invokeConfirmation="false" /> |
|
</saw:clientImplementation> |
|
</saw:action> |
|
<saw:caption> |
|
<saw:text>Gastos por Servicio / |
|
Entidad</saw:text> |
|
</saw:caption> |
|
</saw:actionLink> |
|
<saw:actionLink xsi:type="saw:actionLink" |
|
actionLinkID="e141a2f0e165d683"> |
|
<saw:action> |
|
<saw:actionName>Navigate To BI |
|
Content</saw:actionName> |
|
<saw:parameters allowExtraParameters="true"> |
|
<saw:parameter name="__navigateToBIContent__" |
|
type="string" mandatory="true" removable="true" |
|
order="999" multiValues="false"> |
|
<saw:prompt> |
|
__navigateToBIContent__</saw:prompt> |
|
</saw:parameter> |
|
</saw:parameters> |
|
<saw:assignments> |
|
<saw:assign xsi:type="saw:stringAssign" |
|
name="__navigateToBIContent__" fixed="true" |
|
hidden="true" parentFixed="true" |
|
parentHidden="true"> |
|
<saw:value> |
|
/shared/SiCi/Ejecucion_por_Programa</saw:value> |
|
</saw:assign> |
|
</saw:assignments> |
|
<saw:implementation xsi:type="saw:ScriptActionType" |
|
executeOnClient="true"> |
|
<saw:functionName> |
|
__navigateToBIContent__</saw:functionName> |
|
<saw:scriptLanguage> |
|
JScript</saw:scriptLanguage> |
|
<saw:scriptPath /> |
|
</saw:implementation> |
|
<saw:clientImplementation> |
|
<saw:customisation invokeConfirmation="false" /> |
|
</saw:clientImplementation> |
|
</saw:action> |
|
<saw:caption> |
|
<saw:text>Gastos por Programas</saw:text> |
|
</saw:caption> |
|
</saw:actionLink> |
|
<saw:actionLink xsi:type="saw:actionLink" |
|
actionLinkID="b198588c67f40283"> |
|
<saw:action> |
|
<saw:actionName>Navigate To BI |
|
Content</saw:actionName> |
|
<saw:parameters allowExtraParameters="true"> |
|
<saw:parameter name="__navigateToBIContent__" |
|
type="string" mandatory="true" removable="true" |
|
order="999" multiValues="false"> |
|
<saw:prompt> |
|
__navigateToBIContent__</saw:prompt> |
|
</saw:parameter> |
|
</saw:parameters> |
|
<saw:assignments> |
|
<saw:assign xsi:type="saw:stringAssign" |
|
name="__navigateToBIContent__" fixed="true" |
|
hidden="true" parentFixed="true" |
|
parentHidden="true"> |
|
<saw:value> |
|
/shared/SiCi/Ejecucion_por_Objeto_Gasto</saw:value> |
|
</saw:assign> |
|
</saw:assignments> |
|
<saw:implementation xsi:type="saw:ScriptActionType" |
|
executeOnClient="true"> |
|
<saw:functionName> |
|
__navigateToBIContent__</saw:functionName> |
|
<saw:scriptLanguage> |
|
JScript</saw:scriptLanguage> |
|
<saw:scriptPath /> |
|
</saw:implementation> |
|
<saw:clientImplementation> |
|
<saw:customisation invokeConfirmation="false" /> |
|
</saw:clientImplementation> |
|
</saw:action> |
|
<saw:caption> |
|
<saw:text>Gastos por Objeto del Gasto</saw:text> |
|
</saw:caption> |
|
</saw:actionLink> |
|
<saw:actionLink xsi:type="saw:actionLink" |
|
actionLinkID="1772066e4d56eac4"> |
|
<saw:action> |
|
<saw:actionName>Navigate To BI |
|
Content</saw:actionName> |
|
<saw:parameters allowExtraParameters="true"> |
|
<saw:parameter name="__navigateToBIContent__" |
|
type="string" mandatory="true" removable="true" |
|
order="999" multiValues="false"> |
|
<saw:prompt> |
|
__navigateToBIContent__</saw:prompt> |
|
</saw:parameter> |
|
</saw:parameters> |
|
<saw:assignments> |
|
<saw:assign xsi:type="saw:stringAssign" |
|
name="__navigateToBIContent__" fixed="true" |
|
hidden="true" parentFixed="true" |
|
parentHidden="true"> |
|
<saw:value> |
|
/shared/SiCi/Ejecucion_por_Fuente_Financiamiento</saw:value> |
|
</saw:assign> |
|
</saw:assignments> |
|
<saw:implementation xsi:type="saw:ScriptActionType" |
|
executeOnClient="true"> |
|
<saw:functionName> |
|
__navigateToBIContent__</saw:functionName> |
|
<saw:scriptLanguage> |
|
JScript</saw:scriptLanguage> |
|
<saw:scriptPath /> |
|
</saw:implementation> |
|
<saw:clientImplementation> |
|
<saw:customisation invokeConfirmation="false" /> |
|
</saw:clientImplementation> |
|
</saw:action> |
|
<saw:caption> |
|
<saw:text>Gastos por Fuente de |
|
Financiamiento</saw:text> |
|
</saw:caption> |
|
</saw:actionLink> |
|
<saw:actionLink xsi:type="saw:actionLink" |
|
actionLinkID="f4adf43c7807e275"> |
|
<saw:action> |
|
<saw:actionName>Navigate To BI |
|
Content</saw:actionName> |
|
<saw:parameters allowExtraParameters="true"> |
|
<saw:parameter name="__navigateToBIContent__" |
|
type="string" mandatory="true" removable="true" |
|
order="999" multiValues="false"> |
|
<saw:prompt> |
|
__navigateToBIContent__</saw:prompt> |
|
</saw:parameter> |
|
</saw:parameters> |
|
<saw:assignments> |
|
<saw:assign xsi:type="saw:stringAssign" |
|
name="__navigateToBIContent__" fixed="true" |
|
hidden="true" parentFixed="true" |
|
parentHidden="true"> |
|
<saw:value> |
|
/shared/SiCi/Ejecucion_por_Finalidad_Funcion</saw:value> |
|
</saw:assign> |
|
</saw:assignments> |
|
<saw:implementation xsi:type="saw:ScriptActionType" |
|
executeOnClient="true"> |
|
<saw:functionName> |
|
__navigateToBIContent__</saw:functionName> |
|
<saw:scriptLanguage> |
|
JScript</saw:scriptLanguage> |
|
<saw:scriptPath /> |
|
</saw:implementation> |
|
<saw:clientImplementation> |
|
<saw:customisation invokeConfirmation="false" /> |
|
</saw:clientImplementation> |
|
</saw:action> |
|
<saw:caption> |
|
<saw:text>Gastos por Finalidad |
|
Función</saw:text> |
|
</saw:caption> |
|
</saw:actionLink> |
|
<saw:actionLink xsi:type="saw:actionLink" |
|
actionLinkID="d43846e80d3c0b69"> |
|
<saw:action> |
|
<saw:actionName>Navigate To BI |
|
Content</saw:actionName> |
|
<saw:parameters allowExtraParameters="true"> |
|
<saw:parameter name="__navigateToBIContent__" |
|
type="string" mandatory="true" removable="true" |
|
order="999" multiValues="false"> |
|
<saw:prompt> |
|
__navigateToBIContent__</saw:prompt> |
|
</saw:parameter> |
|
</saw:parameters> |
|
<saw:assignments> |
|
<saw:assign xsi:type="saw:stringAssign" |
|
name="__navigateToBIContent__" fixed="true" |
|
hidden="true" parentFixed="true" |
|
parentHidden="true"> |
|
<saw:value> |
|
/shared/SiCi/Ejecucion_por_Caracter</saw:value> |
|
</saw:assign> |
|
</saw:assignments> |
|
<saw:implementation xsi:type="saw:ScriptActionType" |
|
executeOnClient="true"> |
|
<saw:functionName> |
|
__navigateToBIContent__</saw:functionName> |
|
<saw:scriptLanguage> |
|
JScript</saw:scriptLanguage> |
|
<saw:scriptPath /> |
|
</saw:implementation> |
|
<saw:clientImplementation> |
|
<saw:customisation invokeConfirmation="false" /> |
|
</saw:clientImplementation> |
|
</saw:action> |
|
<saw:caption> |
|
<saw:text>Gastos por |
|
Carácter</saw:text> |
|
</saw:caption> |
|
</saw:actionLink> |
|
</saw:actionLinks> |
|
</saw:formatSpec> |
|
</saw:displayFormat> |
|
<saw:columnHeading> |
|
<saw:displayFormat> |
|
<saw:formatSpec interaction="default" /> |
|
</saw:displayFormat> |
|
<saw:caption> |
|
<saw:text>Devengado</saw:text> |
|
</saw:caption> |
|
</saw:columnHeading> |
|
<saw:tableHeading> |
|
<saw:caption> |
|
<saw:text>Indicadores Credito</saw:text> |
|
</saw:caption> |
|
</saw:tableHeading> |
|
<saw:columnFormula> |
|
<sawx:expr xsi:type="sawx:sqlExpression">"Indicadores |
|
Credito"."$ Devengado"</sawx:expr> |
|
</saw:columnFormula> |
|
</saw:column> |
|
<saw:column columnID="c10" xsi:type="saw:regularColumn" |
|
forceGroupBy="true"> |
|
<saw:displayFormat> |
|
<saw:formatSpec suppress="default" interaction="action"> |
|
<saw:dataFormat xsi:type="saw:currency" |
|
currencyTag="loc:es-AR" commas="true" |
|
negativeType="minus" minDigits="2" maxDigits="2" /> |
|
<saw:actionLinks> |
|
<saw:actionLink xsi:type="saw:actionLink" |
|
actionLinkID="d05885873ef9c414"> |
|
<saw:action> |
|
<saw:actionName>Navigate To BI |
|
Content</saw:actionName> |
|
<saw:parameters allowExtraParameters="true"> |
|
<saw:parameter name="__navigateToBIContent__" |
|
type="string" mandatory="true" removable="true" |
|
order="999" multiValues="false"> |
|
<saw:prompt> |
|
__navigateToBIContent__</saw:prompt> |
|
</saw:parameter> |
|
</saw:parameters> |
|
<saw:assignments> |
|
<saw:assign xsi:type="saw:stringAssign" |
|
name="__navigateToBIContent__" fixed="true" |
|
hidden="true" parentFixed="true" |
|
parentHidden="true"> |
|
<saw:value> |
|
/shared/SiCi/Ejecucion_por_Servicio</saw:value> |
|
</saw:assign> |
|
</saw:assignments> |
|
<saw:implementation xsi:type="saw:ScriptActionType" |
|
executeOnClient="true"> |
|
<saw:functionName> |
|
__navigateToBIContent__</saw:functionName> |
|
<saw:scriptLanguage> |
|
JScript</saw:scriptLanguage> |
|
<saw:scriptPath /> |
|
</saw:implementation> |
|
<saw:clientImplementation> |
|
<saw:customisation invokeConfirmation="false" /> |
|
</saw:clientImplementation> |
|
</saw:action> |
|
<saw:caption> |
|
<saw:text>Gastos por Servicio / |
|
Entidad</saw:text> |
|
</saw:caption> |
|
</saw:actionLink> |
|
<saw:actionLink xsi:type="saw:actionLink" |
|
actionLinkID="d263dd63277a762c"> |
|
<saw:action> |
|
<saw:actionName>Navigate To BI |
|
Content</saw:actionName> |
|
<saw:parameters allowExtraParameters="true"> |
|
<saw:parameter name="__navigateToBIContent__" |
|
type="string" mandatory="true" removable="true" |
|
order="999" multiValues="false"> |
|
<saw:prompt> |
|
__navigateToBIContent__</saw:prompt> |
|
</saw:parameter> |
|
</saw:parameters> |
|
<saw:assignments> |
|
<saw:assign xsi:type="saw:stringAssign" |
|
name="__navigateToBIContent__" fixed="true" |
|
hidden="true" parentFixed="true" |
|
parentHidden="true"> |
|
<saw:value> |
|
/shared/SiCi/Ejecucion_por_Programa</saw:value> |
|
</saw:assign> |
|
</saw:assignments> |
|
<saw:implementation xsi:type="saw:ScriptActionType" |
|
executeOnClient="true"> |
|
<saw:functionName> |
|
__navigateToBIContent__</saw:functionName> |
|
<saw:scriptLanguage> |
|
JScript</saw:scriptLanguage> |
|
<saw:scriptPath /> |
|
</saw:implementation> |
|
<saw:clientImplementation> |
|
<saw:customisation invokeConfirmation="false" /> |
|
</saw:clientImplementation> |
|
</saw:action> |
|
<saw:caption> |
|
<saw:text>Gastos por Programas</saw:text> |
|
</saw:caption> |
|
</saw:actionLink> |
|
<saw:actionLink xsi:type="saw:actionLink" |
|
actionLinkID="14de79d6316e652d"> |
|
<saw:action> |
|
<saw:actionName>Navigate To BI |
|
Content</saw:actionName> |
|
<saw:parameters allowExtraParameters="true"> |
|
<saw:parameter name="__navigateToBIContent__" |
|
type="string" mandatory="true" removable="true" |
|
order="999" multiValues="false"> |
|
<saw:prompt> |
|
__navigateToBIContent__</saw:prompt> |
|
</saw:parameter> |
|
</saw:parameters> |
|
<saw:assignments> |
|
<saw:assign xsi:type="saw:stringAssign" |
|
name="__navigateToBIContent__" fixed="true" |
|
hidden="true" parentFixed="true" |
|
parentHidden="true"> |
|
<saw:value> |
|
/shared/SiCi/Ejecucion_por_Objeto_Gasto</saw:value> |
|
</saw:assign> |
|
</saw:assignments> |
|
<saw:implementation xsi:type="saw:ScriptActionType" |
|
executeOnClient="true"> |
|
<saw:functionName> |
|
__navigateToBIContent__</saw:functionName> |
|
<saw:scriptLanguage> |
|
JScript</saw:scriptLanguage> |
|
<saw:scriptPath /> |
|
</saw:implementation> |
|
<saw:clientImplementation> |
|
<saw:customisation invokeConfirmation="false" /> |
|
</saw:clientImplementation> |
|
</saw:action> |
|
<saw:caption> |
|
<saw:text>Gastos por Objeto del Gasto</saw:text> |
|
</saw:caption> |
|
</saw:actionLink> |
|
<saw:actionLink xsi:type="saw:actionLink" |
|
actionLinkID="ddc3362be26960f5"> |
|
<saw:action> |
|
<saw:actionName>Navigate To BI |
|
Content</saw:actionName> |
|
<saw:parameters allowExtraParameters="true"> |
|
<saw:parameter name="__navigateToBIContent__" |
|
type="string" mandatory="true" removable="true" |
|
order="999" multiValues="false"> |
|
<saw:prompt> |
|
__navigateToBIContent__</saw:prompt> |
|
</saw:parameter> |
|
</saw:parameters> |
|
<saw:assignments> |
|
<saw:assign xsi:type="saw:stringAssign" |
|
name="__navigateToBIContent__" fixed="true" |
|
hidden="true" parentFixed="true" |
|
parentHidden="true"> |
|
<saw:value> |
|
/shared/SiCi/Ejecucion_por_Fuente_Financiamiento</saw:value> |
|
</saw:assign> |
|
</saw:assignments> |
|
<saw:implementation xsi:type="saw:ScriptActionType" |
|
executeOnClient="true"> |
|
<saw:functionName> |
|
__navigateToBIContent__</saw:functionName> |
|
<saw:scriptLanguage> |
|
JScript</saw:scriptLanguage> |
|
<saw:scriptPath /> |
|
</saw:implementation> |
|
<saw:clientImplementation> |
|
<saw:customisation invokeConfirmation="false" /> |
|
</saw:clientImplementation> |
|
</saw:action> |
|
<saw:caption> |
|
<saw:text>Gastos por Fuente de |
|
Financiamiento</saw:text> |
|
</saw:caption> |
|
</saw:actionLink> |
|
<saw:actionLink xsi:type="saw:actionLink" |
|
actionLinkID="a5f6ee33a01113f5"> |
|
<saw:action> |
|
<saw:actionName>Navigate To BI |
|
Content</saw:actionName> |
|
<saw:parameters allowExtraParameters="true"> |
|
<saw:parameter name="__navigateToBIContent__" |
|
type="string" mandatory="true" removable="true" |
|
order="999" multiValues="false"> |
|
<saw:prompt> |
|
__navigateToBIContent__</saw:prompt> |
|
</saw:parameter> |
|
</saw:parameters> |
|
<saw:assignments> |
|
<saw:assign xsi:type="saw:stringAssign" |
|
name="__navigateToBIContent__" fixed="true" |
|
hidden="true" parentFixed="true" |
|
parentHidden="true"> |
|
<saw:value> |
|
/shared/SiCi/Ejecucion_por_Finalidad_Funcion</saw:value> |
|
</saw:assign> |
|
</saw:assignments> |
|
<saw:implementation xsi:type="saw:ScriptActionType" |
|
executeOnClient="true"> |
|
<saw:functionName> |
|
__navigateToBIContent__</saw:functionName> |
|
<saw:scriptLanguage> |
|
JScript</saw:scriptLanguage> |
|
<saw:scriptPath /> |
|
</saw:implementation> |
|
<saw:clientImplementation> |
|
<saw:customisation invokeConfirmation="false" /> |
|
</saw:clientImplementation> |
|
</saw:action> |
|
<saw:caption> |
|
<saw:text>Gastos por Finalidad |
|
Función</saw:text> |
|
</saw:caption> |
|
</saw:actionLink> |
|
<saw:actionLink xsi:type="saw:actionLink" |
|
actionLinkID="962768cd2b2fb9e9"> |
|
<saw:action> |
|
<saw:actionName>Navigate To BI |
|
Content</saw:actionName> |
|
<saw:parameters allowExtraParameters="true"> |
|
<saw:parameter name="__navigateToBIContent__" |
|
type="string" mandatory="true" removable="true" |
|
order="999" multiValues="false"> |
|
<saw:prompt> |
|
__navigateToBIContent__</saw:prompt> |
|
</saw:parameter> |
|
</saw:parameters> |
|
<saw:assignments> |
|
<saw:assign xsi:type="saw:stringAssign" |
|
name="__navigateToBIContent__" fixed="true" |
|
hidden="true" parentFixed="true" |
|
parentHidden="true"> |
|
<saw:value> |
|
/shared/SiCi/Ejecucion_por_Caracter</saw:value> |
|
</saw:assign> |
|
</saw:assignments> |
|
<saw:implementation xsi:type="saw:ScriptActionType" |
|
executeOnClient="true"> |
|
<saw:functionName> |
|
__navigateToBIContent__</saw:functionName> |
|
<saw:scriptLanguage> |
|
JScript</saw:scriptLanguage> |
|
<saw:scriptPath /> |
|
</saw:implementation> |
|
<saw:clientImplementation> |
|
<saw:customisation invokeConfirmation="false" /> |
|
</saw:clientImplementation> |
|
</saw:action> |
|
<saw:caption> |
|
<saw:text>Gastos por |
|
Carácter</saw:text> |
|
</saw:caption> |
|
</saw:actionLink> |
|
</saw:actionLinks> |
|
</saw:formatSpec> |
|
</saw:displayFormat> |
|
<saw:columnHeading> |
|
<saw:displayFormat> |
|
<saw:formatSpec interaction="default" /> |
|
</saw:displayFormat> |
|
<saw:caption> |
|
<saw:text>Pagado</saw:text> |
|
</saw:caption> |
|
</saw:columnHeading> |
|
<saw:tableHeading> |
|
<saw:caption> |
|
<saw:text>Indicadores Credito</saw:text> |
|
</saw:caption> |
|
</saw:tableHeading> |
|
<saw:columnFormula> |
|
<sawx:expr xsi:type="sawx:sqlExpression">"Indicadores |
|
Credito"."$ Pagado"</sawx:expr> |
|
</saw:columnFormula> |
|
</saw:column> |
|
<saw:column columnID="c11" xsi:type="saw:regularColumn" |
|
forceGroupBy="true"> |
|
<saw:displayFormat> |
|
<saw:formatSpec suppress="default" interaction="default"> |
|
<saw:dataFormat xsi:type="saw:percent" commas="true" |
|
negativeType="minus" minDigits="2" maxDigits="2" /> |
|
</saw:formatSpec> |
|
</saw:displayFormat> |
|
<saw:columnHeading> |
|
<saw:displayFormat> |
|
<saw:formatSpec interaction="default" /> |
|
</saw:displayFormat> |
|
<saw:caption> |
|
<saw:text>% Devengado</saw:text> |
|
</saw:caption> |
|
</saw:columnHeading> |
|
<saw:tableHeading> |
|
<saw:caption> |
|
<saw:text>Indicadores Credito</saw:text> |
|
</saw:caption> |
|
</saw:tableHeading> |
|
<saw:columnFormula> |
|
<sawx:expr xsi:type="sawx:sqlExpression"> |
|
IFNULL("Indicadores Credito"."% Devengado", |
|
0)</sawx:expr> |
|
</saw:columnFormula> |
|
</saw:column> |
|
<saw:column columnID="c25" xsi:type="saw:regularColumn" |
|
forceGroupBy="true"> |
|
<saw:columnFormula> |
|
<sawx:expr xsi:type="sawx:sqlExpression">"Ejercicio |
|
Presupuestario"."Cod. Ejercicio |
|
Presupuestario"</sawx:expr> |
|
</saw:columnFormula> |
|
</saw:column> |
|
<saw:column columnID="c26" xsi:type="saw:regularColumn" |
|
forceGroupBy="true"> |
|
<saw:columnFormula> |
|
<sawx:expr xsi:type="sawx:sqlExpression">"Ejercicio |
|
Presupuestario".Leyenda_Fecha_Act</sawx:expr> |
|
</saw:columnFormula> |
|
</saw:column> |
|
</saw:columns> |
|
<saw:filter> |
|
<sawx:expr xsi:type="sawx:logical" op="and"> |
|
<sawx:expr xsi:type="sawx:comparison" op="between" |
|
protected="true"> |
|
<sawx:expr xsi:type="sawx:sqlExpression">"Finalidad |
|
Funcion"."Cod. Finalidad"</sawx:expr> |
|
<sawx:expr xsi:type="xsd:decimal">1</sawx:expr> |
|
<sawx:expr xsi:type="xsd:decimal">5</sawx:expr> |
|
</sawx:expr> |
|
<sawx:expr xsi:type="sawx:logical" op="and"> |
|
<sawx:expr xsi:type="sawx:comparison" op="equal" |
|
protected="true"> |
|
<sawx:expr xsi:type="sawx:sqlExpression">"Sector |
|
Institucional"."Cod. Sector"</sawx:expr> |
|
<sawx:expr xsi:type="xsd:decimal">1</sawx:expr> |
|
</sawx:expr> |
|
<sawx:expr xsi:type="sawx:comparison" op="equal" |
|
protected="true"> |
|
<sawx:expr xsi:type="sawx:sqlExpression">"Sector |
|
Institucional"."Cod. Subsector"</sawx:expr> |
|
<sawx:expr xsi:type="xsd:decimal">1</sawx:expr> |
|
</sawx:expr> |
|
<sawx:expr xsi:type="sawx:special" op="prompted"> |
|
<sawx:expr xsi:type="sawx:sqlExpression">"Sector |
|
Institucional"."Cod. y Desc. Caracter"</sawx:expr> |
|
</sawx:expr> |
|
</sawx:expr> |
|
<sawx:expr xsi:type="sawx:logical" op="and"> |
|
<sawx:expr xsi:type="sawx:special" op="prompted" |
|
protected="true"> |
|
<sawx:expr xsi:type="sawx:sqlExpression"> |
|
Institucion."Cod. y Desc. Jurisdiccion"</sawx:expr> |
|
</sawx:expr> |
|
<sawx:expr xsi:type="sawx:special" op="prompted"> |
|
<sawx:expr xsi:type="sawx:sqlExpression"> |
|
Institucion."Cod. Jurisdiccion"</sawx:expr> |
|
</sawx:expr> |
|
<sawx:expr xsi:type="sawx:special" op="prompted"> |
|
<sawx:expr xsi:type="sawx:sqlExpression"> |
|
Institucion."Cod. y Desc. Subjurisdiccion"</sawx:expr> |
|
</sawx:expr> |
|
<sawx:expr xsi:type="sawx:special" op="prompted"> |
|
<sawx:expr xsi:type="sawx:sqlExpression"> |
|
Institucion."Cod. y Desc. Entidad"</sawx:expr> |
|
</sawx:expr> |
|
</sawx:expr> |
|
<sawx:expr xsi:type="sawx:logical" op="and"> |
|
<sawx:expr xsi:type="sawx:special" op="prompted"> |
|
<sawx:expr xsi:type="sawx:sqlExpression">"Finalidad |
|
Funcion"."Cod. y Desc. Finalidad"</sawx:expr> |
|
</sawx:expr> |
|
<sawx:expr xsi:type="sawx:special" op="prompted"> |
|
<sawx:expr xsi:type="sawx:sqlExpression">"Finalidad |
|
Funcion"."Cod. y Desc. Funcion"</sawx:expr> |
|
</sawx:expr> |
|
<sawx:expr xsi:type="sawx:special" op="prompted"> |
|
<sawx:expr xsi:type="sawx:sqlExpression">"Finalidad |
|
Funcion"."Cod. y Desc. FinFun"</sawx:expr> |
|
</sawx:expr> |
|
</sawx:expr> |
|
<sawx:expr xsi:type="sawx:logical" op="and"> |
|
<sawx:expr xsi:type="sawx:special" op="prompted"> |
|
<sawx:expr xsi:type="sawx:sqlExpression">"Fuente |
|
Financiamiento"."Cod. y Desc. Procedencia"</sawx:expr> |
|
</sawx:expr> |
|
<sawx:expr xsi:type="sawx:special" op="prompted"> |
|
<sawx:expr xsi:type="sawx:sqlExpression">"Fuente |
|
Financiamiento"."Cod. y Desc. Fuente"</sawx:expr> |
|
</sawx:expr> |
|
</sawx:expr> |
|
<sawx:expr xsi:type="sawx:special" op="prompted"> |
|
<sawx:expr xsi:type="sawx:sqlExpression">"Ubicacion |
|
Geografica"."Cod. y Desc. Ubicacion |
|
Geografica"</sawx:expr> |
|
</sawx:expr> |
|
<sawx:expr xsi:type="sawx:logical" op="and"> |
|
<sawx:expr xsi:type="sawx:special" op="prompted"> |
|
<sawx:expr xsi:type="sawx:sqlExpression">"Objeto |
|
Gasto"."Cod. y Desc. Inciso"</sawx:expr> |
|
</sawx:expr> |
|
<sawx:expr xsi:type="sawx:special" op="prompted"> |
|
<sawx:expr xsi:type="sawx:sqlExpression">"Objeto |
|
Gasto"."Desc. Inciso"</sawx:expr> |
|
</sawx:expr> |
|
<sawx:expr xsi:type="sawx:special" op="prompted"> |
|
<sawx:expr xsi:type="sawx:sqlExpression">"Objeto |
|
Gasto"."Cod. y Desc. Principal"</sawx:expr> |
|
</sawx:expr> |
|
<sawx:expr xsi:type="sawx:special" op="prompted"> |
|
<sawx:expr xsi:type="sawx:sqlExpression">"Objeto |
|
Gasto"."Desc. Principal"</sawx:expr> |
|
</sawx:expr> |
|
</sawx:expr> |
|
<sawx:expr xsi:type="sawx:logical" op="and"> |
|
<sawx:expr xsi:type="sawx:special" op="prompted"> |
|
<sawx:expr xsi:type="sawx:sqlExpression">"Clasificador |
|
Economico"."Cod. 3 Digitos"</sawx:expr> |
|
</sawx:expr> |
|
<sawx:expr xsi:type="sawx:special" op="prompted"> |
|
<sawx:expr xsi:type="sawx:sqlExpression">"Clasificador |
|
Economico"."Cod. 4 Digitos"</sawx:expr> |
|
</sawx:expr> |
|
<sawx:expr xsi:type="sawx:special" op="prompted"> |
|
<sawx:expr xsi:type="sawx:sqlExpression">"Clasificador |
|
Economico"."Cod. 5 Digitos"</sawx:expr> |
|
</sawx:expr> |
|
<sawx:expr xsi:type="sawx:special" op="prompted"> |
|
<sawx:expr xsi:type="sawx:sqlExpression">"Clasificador |
|
Economico"."Cod. 6 Digitos"</sawx:expr> |
|
</sawx:expr> |
|
<sawx:expr xsi:type="sawx:special" op="prompted"> |
|
<sawx:expr xsi:type="sawx:sqlExpression">"Clasificador |
|
Economico"."Cod. 7 Digitos"</sawx:expr> |
|
</sawx:expr> |
|
<sawx:expr xsi:type="sawx:special" op="prompted"> |
|
<sawx:expr xsi:type="sawx:sqlExpression">"Clasificador |
|
Economico"."Cod. 8 Digitos"</sawx:expr> |
|
</sawx:expr> |
|
</sawx:expr> |
|
<sawx:expr xsi:type="sawx:special" op="prompted"> |
|
<sawx:expr xsi:type="sawx:sqlExpression">"Clasificador |
|
Economico"."Desc. 3 Digitos Para Gastos |
|
Corrientes"</sawx:expr> |
|
</sawx:expr> |
|
<sawx:expr xsi:type="sawx:special" op="prompted"> |
|
<sawx:expr xsi:type="sawx:sqlExpression">"Clasificador |
|
Economico"."Desc. 3 Digitos Para Gastos de |
|
Capital"</sawx:expr> |
|
</sawx:expr> |
|
<sawx:expr xsi:type="sawx:special" op="prompted"> |
|
<sawx:expr xsi:type="sawx:sqlExpression"> |
|
Institucion."Cod. Jurisdiccion"</sawx:expr> |
|
</sawx:expr> |
|
<sawx:expr xsi:type="sawx:special" op="prompted"> |
|
<sawx:expr xsi:type="sawx:sqlExpression"> |
|
Institucion."Cod. y Desc. Subjurisdiccion"</sawx:expr> |
|
</sawx:expr> |
|
<sawx:expr xsi:type="sawx:special" op="prompted"> |
|
<sawx:expr xsi:type="sawx:sqlExpression"> |
|
Institucion."Cod. y Desc. Jurisdiccion"</sawx:expr> |
|
</sawx:expr> |
|
<sawx:expr xsi:type="sawx:sql" protected="true">"Ejercicio |
|
Presupuestario"."Cod. Ejercicio Presupuestario" = |
|
"Tiempo"."Ejercicio-Actual"</sawx:expr> |
|
<sawx:expr xsi:type="sawx:special" op="prompted"> |
|
<sawx:expr xsi:type="sawx:sqlExpression">Servicio."Cod. y |
|
Desc. Servicio"</sawx:expr> |
|
</sawx:expr> |
|
<sawx:expr xsi:type="sawx:special" op="prompted"> |
|
<sawx:expr xsi:type="sawx:sqlExpression">"Clasificador |
|
Economico"."Cod. 2 Digitos"</sawx:expr> |
|
</sawx:expr> |
|
<sawx:expr xsi:type="sawx:special" op="prompted"> |
|
<sawx:expr xsi:type="sawx:sqlExpression">"Clasificador |
|
Economico"."Desc. 2 Digitos"</sawx:expr> |
|
</sawx:expr> |
|
</sawx:expr> |
|
</saw:filter> |
|
<saw:columnOrder> |
|
<saw:columnOrderRef columnID="c28" direction="ascending" /> |
|
</saw:columnOrder> |
|
</saw:criteria> |
|
<saw:interactionOptions drill="true" movecolumns="false" |
|
sortcolumns="false" addremovevalues="false" |
|
groupoperations="false" calcitemoperations="false" |
|
showhidesubtotal="false" showhiderunningsum="false" |
|
inclexclcolumns="false" hidecolumns="false" /> |
|
<saw:views currentView="0" textDelivery="compoundView!1" |
|
includeNewColumns="true" parentsBefore="true" |
|
nullSuppress="true"> |
|
<saw:view xsi:type="saw:compoundView" name="compoundView!1"> |
|
<saw:cvTable> |
|
<saw:cvRow> |
|
<saw:cvCell viewName="titleView!1"> |
|
<saw:displayFormat> |
|
<saw:formatSpec width="650" paddingTop="0" |
|
paddingBottom="0" /> |
|
</saw:displayFormat> |
|
</saw:cvCell> |
|
</saw:cvRow> |
|
<saw:cvRow> |
|
<saw:cvCell viewName="pivotTableView!1"> |
|
<saw:displayFormat> |
|
<saw:formatSpec width="650" /> |
|
</saw:displayFormat> |
|
</saw:cvCell> |
|
</saw:cvRow> |
|
<saw:cvRow> |
|
<saw:cvCell viewName="legendView!1"> |
|
<saw:displayFormat> |
|
<saw:formatSpec width="650" /> |
|
</saw:displayFormat> |
|
</saw:cvCell> |
|
</saw:cvRow> |
|
<saw:cvRow> |
|
<saw:cvCell viewName="htmlview!1"> |
|
<saw:displayFormat> |
|
<saw:formatSpec width="650" /> |
|
</saw:displayFormat> |
|
</saw:cvCell> |
|
</saw:cvRow> |
|
<saw:cvRow> |
|
<saw:cvCell viewName="pivotTableView!3"> |
|
<saw:displayFormat> |
|
<saw:formatSpec width="650" /> |
|
</saw:displayFormat> |
|
</saw:cvCell> |
|
</saw:cvRow> |
|
</saw:cvTable> |
|
<saw:pageProps> |
|
<saw:pageHeader /> |
|
<saw:pageFooter /> |
|
</saw:pageProps> |
|
</saw:view> |
|
<saw:view xsi:type="saw:titleView" name="titleView!1" |
|
includeName="false" startedDisplay="dateTime" |
|
helpUrl="fmap:/sici/ejecucion_por_jurisdiccion.html"> |
|
<saw:title> |
|
<saw:caption fmt="text"> |
|
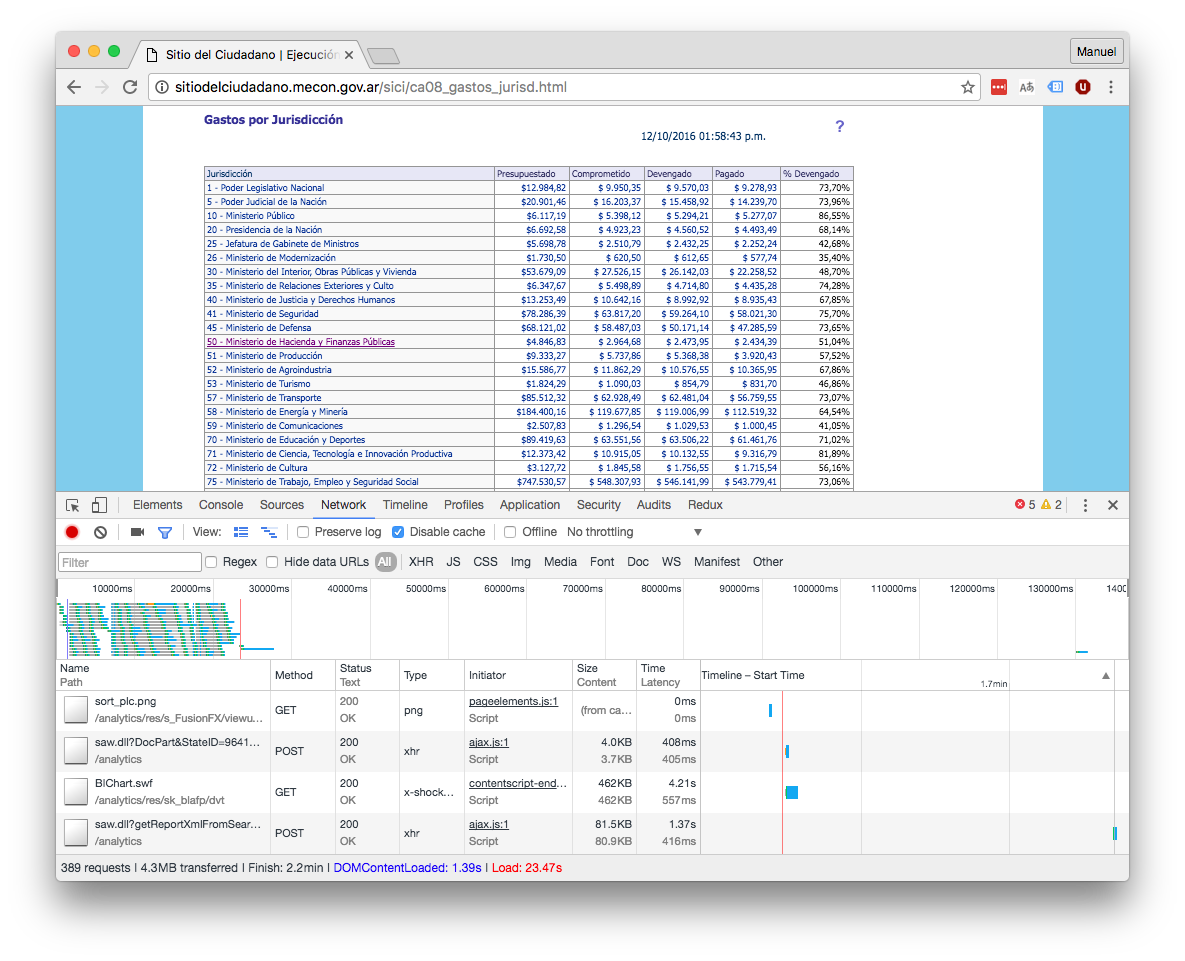
<saw:text>Gastos por Jurisdicción</saw:text> |
|
</saw:caption> |
|
</saw:title> |
|
<saw:createdTime> |
|
<saw:displayFormat> |
|
<saw:formatSpec backgroundColor="#FFFFFF" hAlign="right" |
|
vAlign="middle" paddingTop="0" paddingBottom="0" |
|
wrapText="true" /> |
|
</saw:displayFormat> |
|
<saw:caption> |
|
<saw:text>@</saw:text> |
|
</saw:caption> |
|
</saw:createdTime> |
|
</saw:view> |
|
<saw:view xsi:type="saw:tableView" name="tableView!2"> |
|
<saw:edges> |
|
<saw:edge axis="page" showColumnHeader="true" /> |
|
<saw:edge axis="section" /> |
|
<saw:edge axis="row" showColumnHeader="true"> |
|
<saw:edgeLayers> |
|
<saw:edgeLayer type="column" columnID="c28" /> |
|
<saw:edgeLayer type="column" columnID="c17" /> |
|
<saw:edgeLayer type="column" columnID="c12" /> |
|
<saw:edgeLayer type="column" columnID="c7" /> |
|
<saw:edgeLayer type="column" columnID="c8" /> |
|
<saw:edgeLayer type="column" columnID="c9" /> |
|
<saw:edgeLayer type="column" columnID="c10" /> |
|
<saw:edgeLayer type="column" columnID="c11" /> |
|
<saw:edgeLayer type="column" columnID="c25" /> |
|
<saw:edgeLayer type="column" columnID="c26" /> |
|
</saw:edgeLayers> |
|
</saw:edge> |
|
<saw:edge axis="column" /> |
|
</saw:edges> |
|
</saw:view> |
|
<saw:view xsi:type="saw:pivotTableView" |
|
name="pivotTableView!1"> |
|
<saw:edges> |
|
<saw:edge axis="page" showColumnHeader="true" /> |
|
<saw:edge axis="section" /> |
|
<saw:edge axis="row" showColumnHeader="true"> |
|
<saw:displayGrandTotals> |
|
<saw:displayGrandTotal grandTotalPosition="after" |
|
id="t1"> |
|
<saw:memberFormat> |
|
<saw:caption> |
|
<saw:text>Total</saw:text> |
|
</saw:caption> |
|
<saw:displayFormat /> |
|
</saw:memberFormat> |
|
</saw:displayGrandTotal> |
|
</saw:displayGrandTotals> |
|
<saw:edgeLayers> |
|
<saw:edgeLayer type="column" columnID="c28" |
|
visibility="hidden" /> |
|
<saw:edgeLayer type="column" columnID="c17" |
|
insertPageBreak="false"> |
|
<saw:headerFormat> |
|
<saw:caption> |
|
<saw:text>Jurisdicción</saw:text> |
|
</saw:caption> |
|
<saw:displayFormat> |
|
<saw:formatSpec wrapText="true" /> |
|
</saw:displayFormat> |
|
</saw:headerFormat> |
|
</saw:edgeLayer> |
|
</saw:edgeLayers> |
|
</saw:edge> |
|
<saw:edge axis="column"> |
|
<saw:edgeLayers> |
|
<saw:edgeLayer type="measure" |
|
insertPageBreak="false" /> |
|
</saw:edgeLayers> |
|
</saw:edge> |
|
</saw:edges> |
|
<saw:measuresList> |
|
<saw:measure columnID="c7" /> |
|
<saw:measure columnID="c8" /> |
|
<saw:measure columnID="c9" /> |
|
<saw:measure columnID="c10" /> |
|
<saw:measure columnID="c11" /> |
|
</saw:measuresList> |
|
<saw:sectionContent> |
|
<saw:displayFormat> |
|
<saw:formatSpec width="650" /> |
|
</saw:displayFormat> |
|
</saw:sectionContent> |
|
</saw:view> |
|
<saw:view xsi:type="saw:pivotTableView" |
|
name="pivotTableView!3"> |
|
<saw:edges> |
|
<saw:edge axis="page" showColumnHeader="true" /> |
|
<saw:edge axis="section" /> |
|
<saw:edge axis="row" showColumnHeader="true"> |
|
<saw:displayGrandTotals> |
|
<saw:displayGrandTotal grandTotalPosition="none" |
|
id="t1" /> |
|
</saw:displayGrandTotals> |
|
<saw:edgeLayers> |
|
<saw:edgeLayer type="column" columnID="c26" |
|
insertPageBreak="false"> |
|
<saw:memberFormat> |
|
<saw:displayFormat> |
|
<saw:formatSpec fontFamily="Arial" |
|
fontColor="#000000" backgroundColor="#FFFFFF" |
|
fontSize="10" fontStyle="regular" |
|
fontEffects="none" borderPosition="none" |
|
hAlign="left" /> |
|
</saw:displayFormat> |
|
</saw:memberFormat> |
|
<saw:headerFormat> |
|
<saw:caption> |
|
<saw:text>Los importes se encuentran expresados |
|
en millones de pesos. | Sin Aplicaciones ni |
|
Fuentes Financieras ni Contribuciones y Gastos |
|
Figurativos. | Fuente: eSidif.</saw:text> |
|
</saw:caption> |
|
<saw:displayFormat> |
|
<saw:formatSpec fontFamily="Arial" |
|
fontColor="#000000" backgroundColor="#FFFFFF" |
|
fontSize="10" fontStyle="regular" |
|
fontEffects="none" hAlign="left" |
|
borderPosition="none" /> |
|
</saw:displayFormat> |
|
</saw:headerFormat> |
|
</saw:edgeLayer> |
|
</saw:edgeLayers> |
|
</saw:edge> |
|
<saw:edge axis="column"></saw:edge> |
|
</saw:edges> |
|
<saw:sectionContent> |
|
<saw:displayFormat> |
|
<saw:formatSpec borderPosition="none" /> |
|
</saw:displayFormat> |
|
</saw:sectionContent> |
|
</saw:view> |
|
<saw:view xsi:type="saw:noresultsview" name="noresultsview!1"> |
|
<saw:detail> |
|
<saw:caption fmt="text"> |
|
<saw:text>Los criterios especificados no han dado como |
|
resultado ningún dato. Esto se debe a menudo a |
|
la aplicación de filtros demasiado |
|
restrictivos o que contienen valores incorrectos. |
|
Compruebe los filtros de la solicitud e |
|
inténtelo de nuevo.</saw:text> |
|
</saw:caption> |
|
</saw:detail> |
|
<saw:headline> |
|
<saw:caption fmt="text"> |
|
<saw:text>No hay resultados</saw:text> |
|
</saw:caption> |
|
</saw:headline> |
|
</saw:view> |
|
<saw:view xsi:type="saw:pivotTableView" |
|
name="pivotTableView!2"> |
|
<saw:edges> |
|
<saw:edge axis="page" showColumnHeader="true"> |
|
<saw:edgeLayers /> |
|
</saw:edge> |
|
<saw:edge axis="section"> |
|
<saw:edgeLayers /> |
|
</saw:edge> |
|
<saw:edge axis="row" showColumnHeader="true"> |
|
<saw:edgeLayers> |
|
<saw:edgeLayer type="column" columnID="c12" |
|
insertPageBreak="false" hideDetails="true"> |
|
</saw:edgeLayer> |
|
</saw:edgeLayers> |
|
</saw:edge> |
|
<saw:edge axis="column"> |
|
<saw:edgeLayers> |
|
<saw:edgeLayer type="measure" |
|
insertPageBreak="false" /> |
|
</saw:edgeLayers> |
|
</saw:edge> |
|
</saw:edges> |
|
<saw:measuresList> |
|
<saw:measure columnID="c9" /> |
|
</saw:measuresList> |
|
<saw:nestedViews> |
|
<saw:nestedView position="chart only"> |
|
<saw:view xsi:type="saw:dvtchart" |
|
name="pivotTableView!2::GridChart"> |
|
<saw:canvasFormat width="300" height="250" |
|
showGradient="false"> |
|
<saw:title mode="custom"> |
|
<saw:caption> |
|
<saw:text>Avance Acumulado de la |
|
Ejecución</saw:text> |
|
</saw:caption> |
|
</saw:title> |
|
<saw:gridlines> |
|
<saw:vertical> |
|
<saw:major visible="true" /> |
|
</saw:vertical> |
|
<saw:horizontal> |
|
<saw:major visible="true" /> |
|
<saw:minor visible="true" /> |
|
</saw:horizontal> |
|
</saw:gridlines> |
|
</saw:canvasFormat> |
|
<saw:axesFormats> |
|
<saw:axisFormat axis="Y1"> |
|
<saw:title mode="custom"> |
|
<saw:caption> |
|
<saw:text>Gasto Ejecutado</saw:text> |
|
</saw:caption> |
|
</saw:title> |
|
<saw:labels> |
|
<saw:dataFormat xsi:type="saw:currency" |
|
negativeType="minus" minDigits="2" maxDigits="2" |
|
commas="true" currencyTag="loc:es-AR" /> |
|
</saw:labels> |
|
</saw:axisFormat> |
|
</saw:axesFormats> |
|
<saw:selections> |
|
<saw:measures> |
|
<saw:column measureType="y"> |
|
<saw:columnRef columnID="c9" /> |
|
</saw:column> |
|
</saw:measures> |
|
<saw:seriesGenerators> |
|
<saw:measureLabels /> |
|
</saw:seriesGenerators> |
|
<saw:categories> |
|
<saw:category> |
|
<saw:columnRef columnID="c12" /> |
|
</saw:category> |
|
</saw:categories> |
|
</saw:selections> |
|
<saw:display type="line" subtype="default"> |
|
<saw:style lineStyle="standardLine" effect="2d" /> |
|
</saw:display> |
|
</saw:view> |
|
</saw:nestedView> |
|
</saw:nestedViews> |
|
</saw:view> |
|
<saw:view xsi:type="saw:legendView" name="legendView!1" |
|
across="2"> |
|
<saw:captionFormat position="right" /> |
|
<saw:title> |
|
<saw:caption> |
|
<saw:text>(Los importes de los gráficos |
|
están expresados en millones de |
|
pesos)</saw:text> |
|
</saw:caption> |
|
<saw:displayFormat> |
|
<saw:formatSpec fontColor="#000000" fontSize="10" |
|
fontStyle="italic" /> |
|
</saw:displayFormat> |
|
</saw:title> |
|
<saw:legendTable> |
|
<saw:displayFormat> |
|
<saw:formatSpec borderPosition="none" /> |
|
</saw:displayFormat> |
|
</saw:legendTable> |
|
</saw:view> |
|
<saw:view xsi:type="saw:htmlview" name="htmlview!1"> |
|
<saw:staticText> |
|
<saw:caption fmt="html"> |
|
<saw:text><iframe |
|
src="/analytics/saw.dll?Go&Path=/shared/SiCi/Grafico_Avance_Ejecutado" |
|
frameborder="0" height="350px" |
|
width="400px"></iframe></saw:text> |
|
</saw:caption> |
|
</saw:staticText> |
|
</saw:view> |
|
</saw:views> |
|
<saw:prompts></saw:prompts> |
|
</saw:report> |